Agentic AI 学习笔记:M1-M3 入门三部曲
整理 Andrew Ng Agentic AI 课程 M1-M3 核心内容:什么是 Agentic Workflow、Reflection 设计模式、Tool Use 工具调用与 MCP 协议。
Agentic AI M1–M3 图文笔记
来源:agentic_workflows_M1_learner.pdf | agentic_workflows_M2_learner.pdf | agentic_workflows_M3_learner.pdf 讲师:Andrew Ng
💡 小白注释:M1-M3 是 Agentic AI 的入门三部曲。M1 讲”什么是 Agentic AI”,M2 讲”写完后怎么检查改进”,M3 讲”怎么让 AI 调用外部工具干活”。全文用 💡 标记的都是通俗解释。
目录
- M1:Introduction to Agentic Workflows
- M2:Reflection Design Pattern
- M3:Tool Use
- M1–M3 串起来看
M1:Introduction to Agentic Workflows
1.1 什么是 Agentic Workflow
非 Agentic(零样本):让 AI 一口气从头写到尾,不准改。
Agentic:把任务拆成多个步骤,逐步完成——先列大纲、再调研、写初稿、检查、修改……
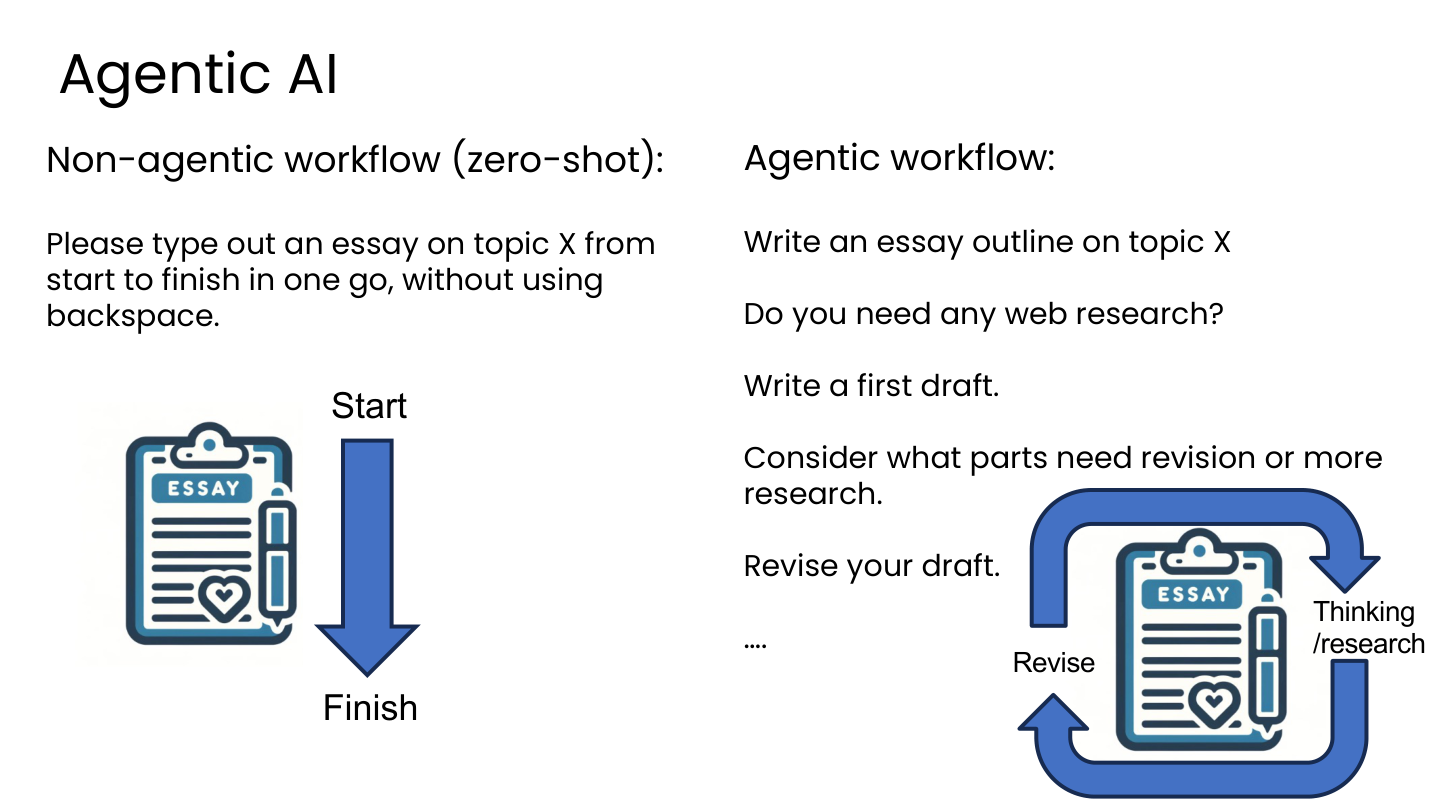
💡 小白注释:非 Agentic 就像考试作文必须一笔写成、不准用橡皮。Agentic 就像正常写作——先打草稿、再修改、再润色。哪种质量更高? obvious。
官方定义:Agentic AI workflow 是一个 LLM-based 应用执行多个步骤来完成任务的过程。
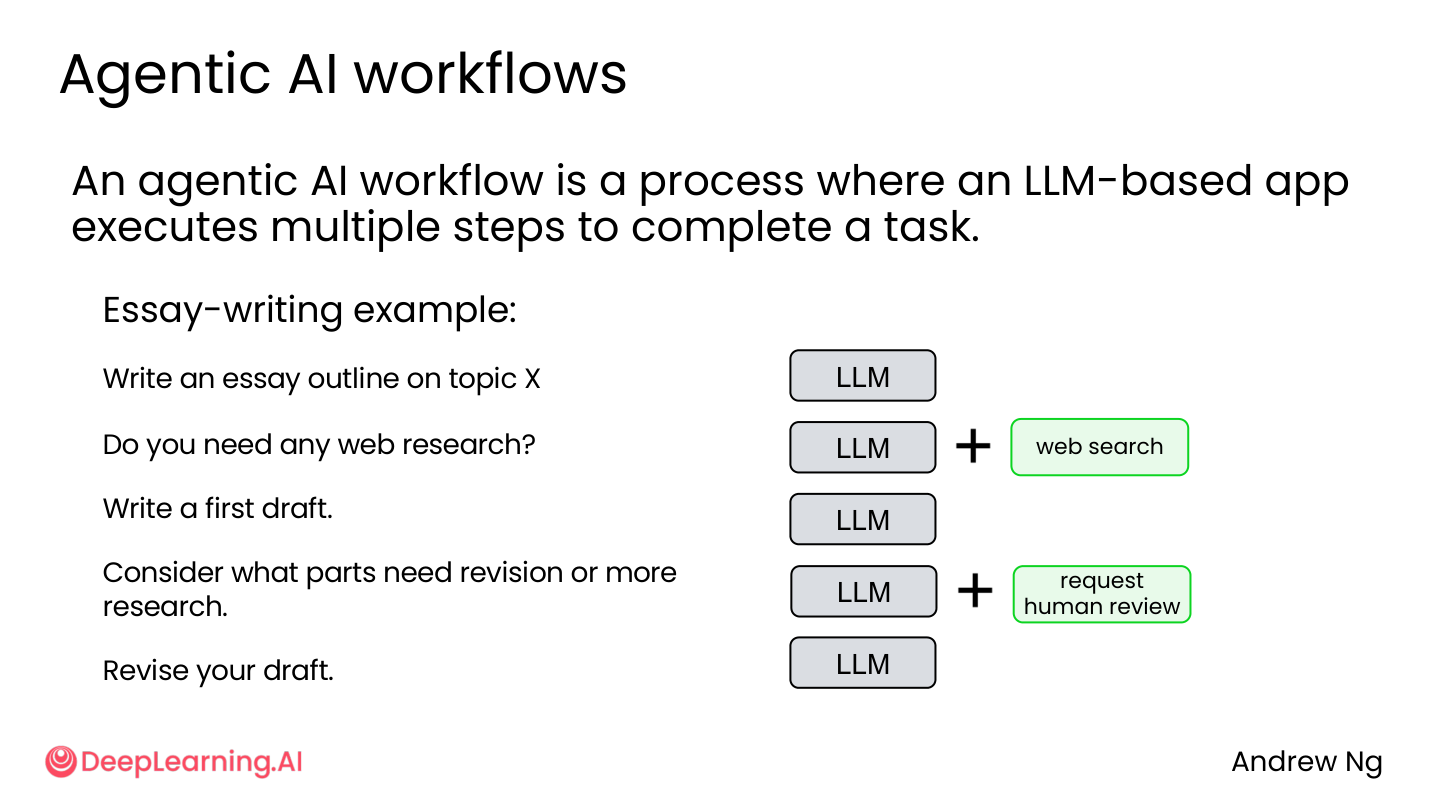
💡 小白注释:M1 的核心就一句话——不要只看最终答案,要看过程能不能被控制。一次性生成是”黑盒”,中间出了什么错你不知道;拆成多步后,每一步都能检查、都能改。
1.2 Agenticness / 自主程度
Agentic AI 不是”有”或”没有”的二分法,而是一个连续谱。
低自主:
- 步骤事先定义好
- 工具调用路径固定
- LLM 只负责文本生成或局部判断
高自主:
- Agent 自己决定下一步做什么
- 会根据中间结果改计划
- 可以自主选择工具,甚至动态创建新工具
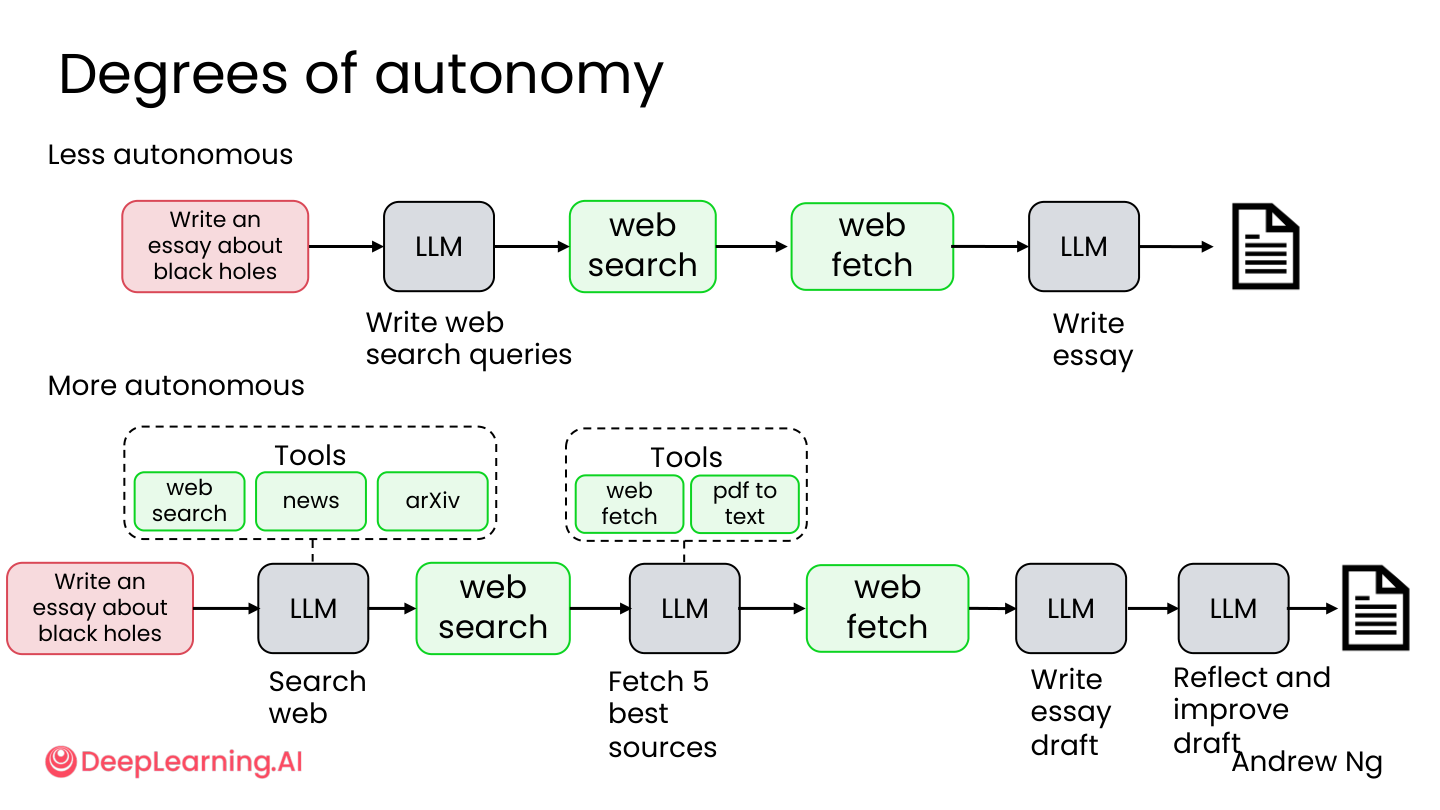

💡 小白注释:就像自动驾驶——低自主是”定速巡航”(你设定速度,车只负责踩油门),高自主是”全自动驾驶”(车自己看路、自己变道、自己找停车场)。M1-M3 主要在讲从”定速巡航”往”辅助驾驶”走的过程。
1.3 为什么要用 Agentic Workflow
研究表明,Agentic 系统的性能显著优于非 Agentic 系统。
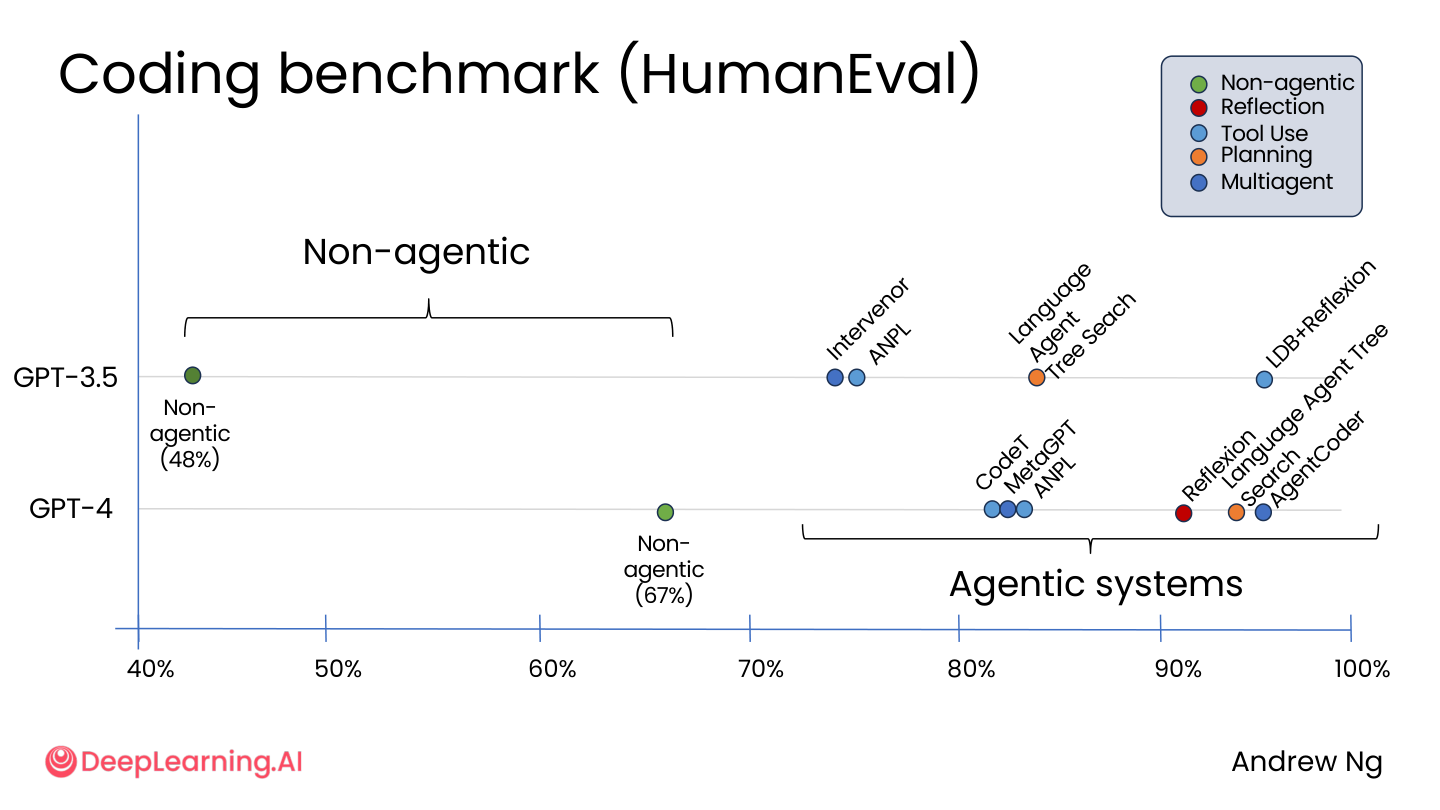
💡 小白注释:这张图来自 HumanEval 编程基准测试。同样是 GPT-4,不加任何 agentic 技巧时通过率约 67%;加上 Reflection、Tool Use、Planning、Multi-agent 后,最好的系统能到 90%+。同样的模型,不同的用法,效果天差地别。
四大好处:
| 好处 | 说明 |
|---|---|
| 性能更好 | 多步迭代比一次性生成质量高 |
| 并行化提速 | 多个搜索/下载可以同时进行 |
| 模块化 | 每个组件可以单独替换升级 |
| 适合复杂任务 | 步骤多了才能处理复杂问题 |
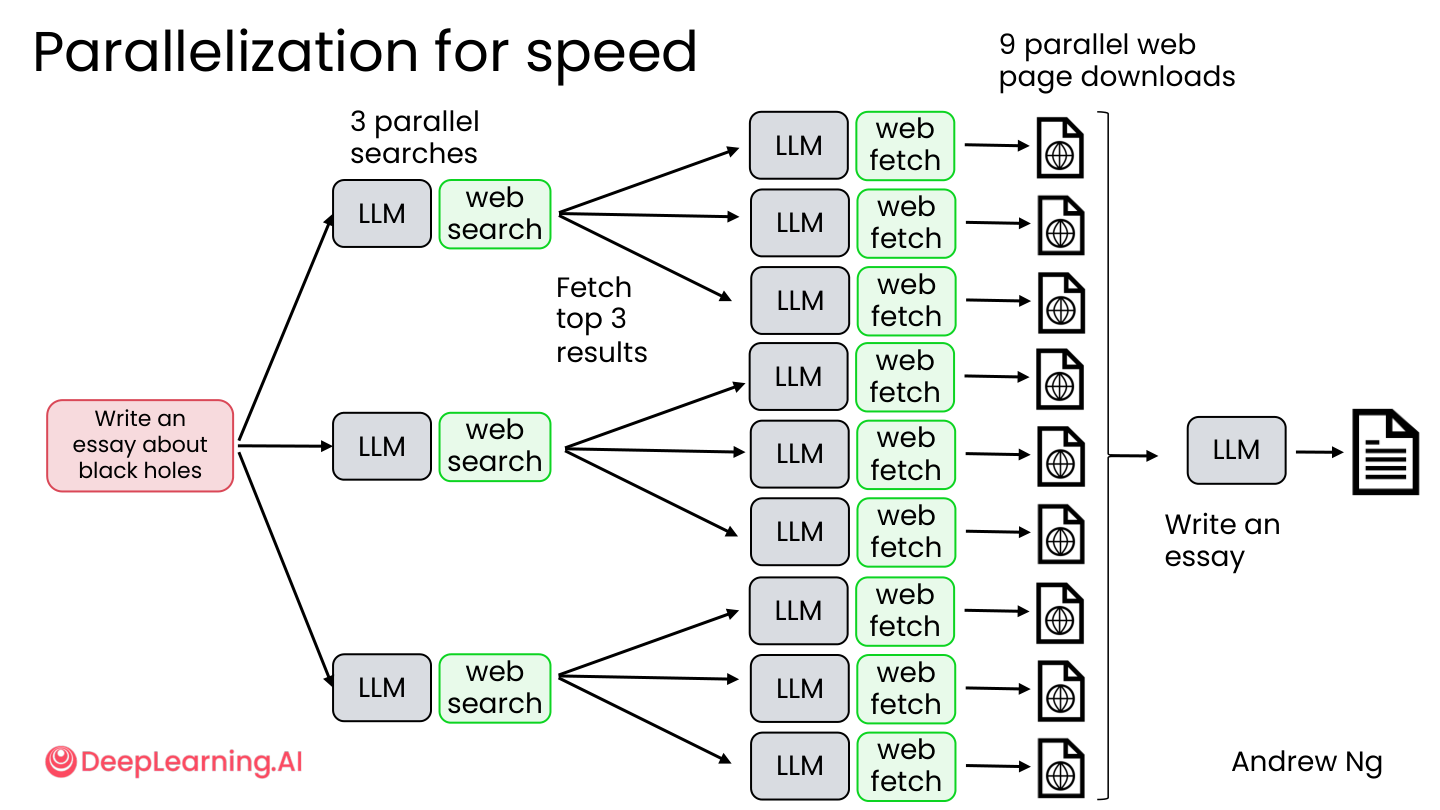
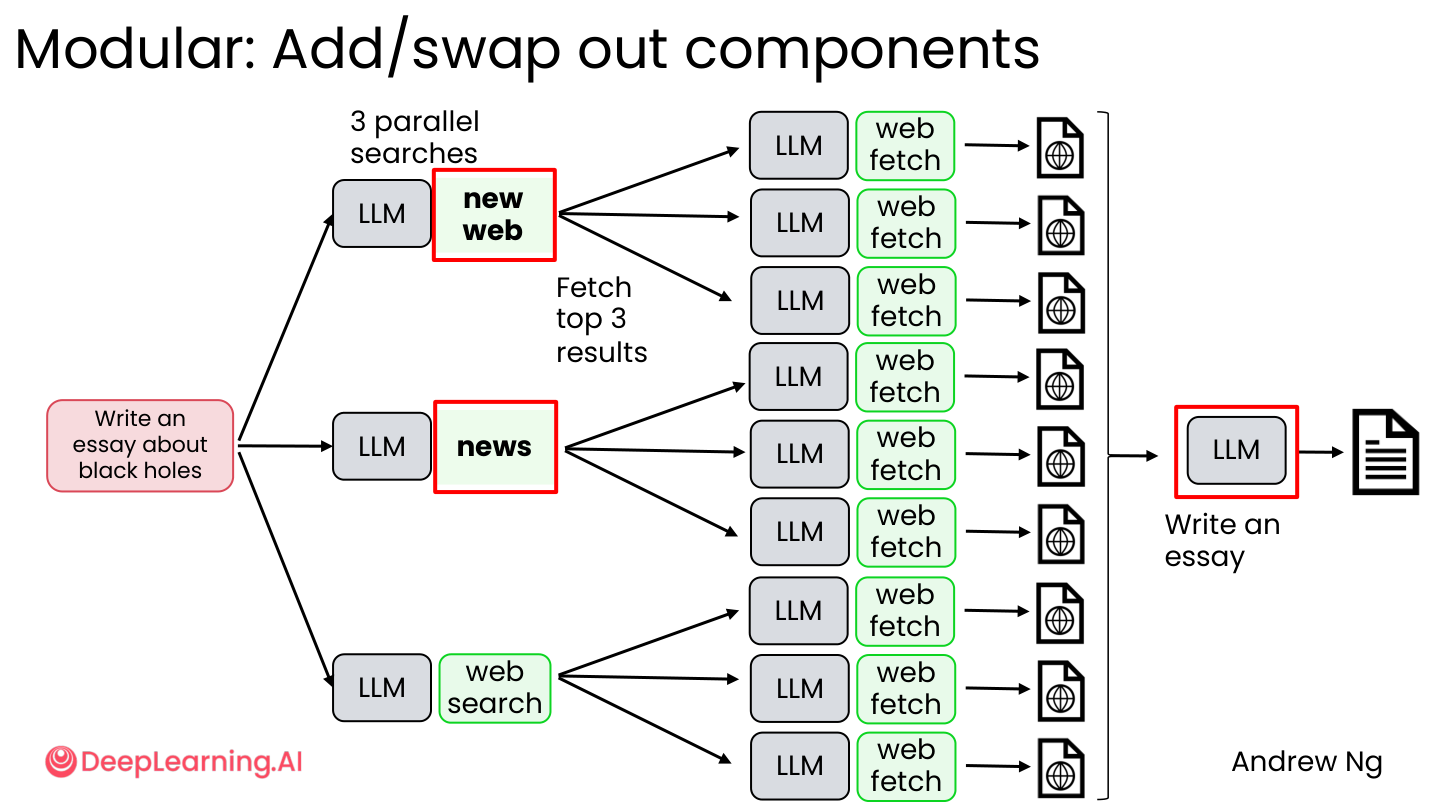
💡 小白注释:并行化就像厨房里有三个灶台同时炒菜;模块化就像乐高——今天用红色积木,明天可以换成蓝色,不用拆整座城堡。
1.4 任务拆解 Task Decomposition
M1 里最重要的工程能力之一就是”拆任务”。
示例:
- 论文写作:大纲 → 调研 → 初稿 → 修改 → 定稿
- 客服邮件:提取信息 → 查订单 → 草拟回复 → 人工审核
- 发票抽取:识别字段 → 结构化 → 校验 → 入库
判断每一步时要问:
- LLM 能不能做?
- Tool 能不能做?
- 是否需要 human-in-the-loop?
💡 小白注释:拆任务的原则——能交给工具的交给工具,能交给人类的交给人类,LLM 只干它最擅长的”理解+生成”。就像餐厅里,厨师炒菜、洗碗机洗碗、服务员传菜,各司其职。
1.5 如何评估 Agentic AI
- Objective evals:用代码判断,适合有标准答案的任务
- Subjective evals:用 LLM-as-judge,适合主观质量任务
- End-to-end eval:看整体结果
- Component-level eval:看每个组件
关键点:trace(轨迹)很重要,error analysis(错误分析)很重要。
💡 小白注释:M1 先告诉你”要评估”,具体怎么评估是 M4 详细讲的。记住:没有考卷,你就不知道改完是好了还是坏了。
M2:Reflection Design Pattern
2.1 Reflection 是什么
Reflection 的核心就是:先生成初稿,再检查,再修改。
可以记成一个简单循环:
1
生成 V1 → 审查/检查 → 修改 V2 → 再检查 → (循环)
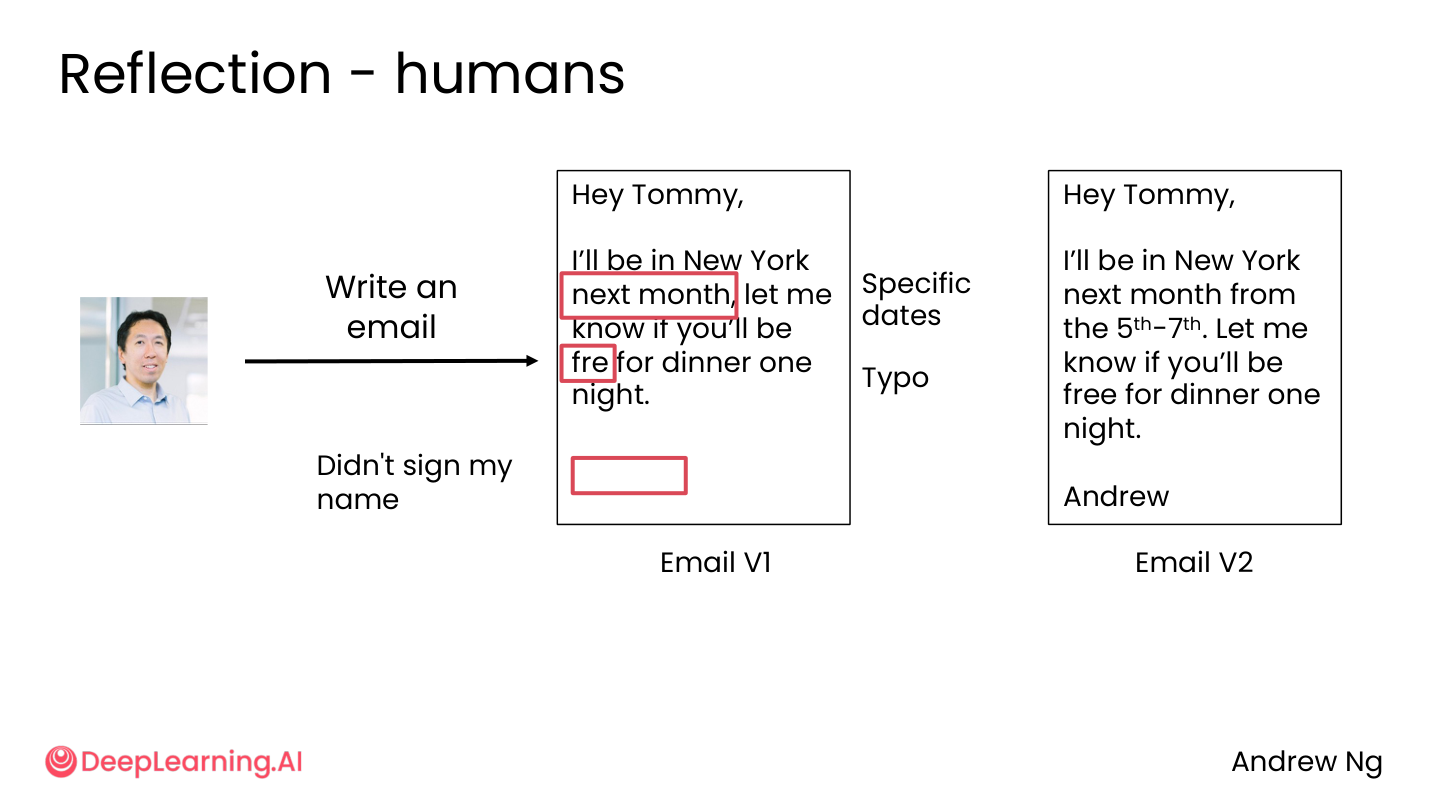
💡 小白注释:你写邮件——第一版经常有错别字、忘签名、语气不对。Reflection 就是”写完先读一遍再发”的习惯。AI 也一样,先生成一版,再自我检查,再改一版。
2.2 Reflection 改进代码
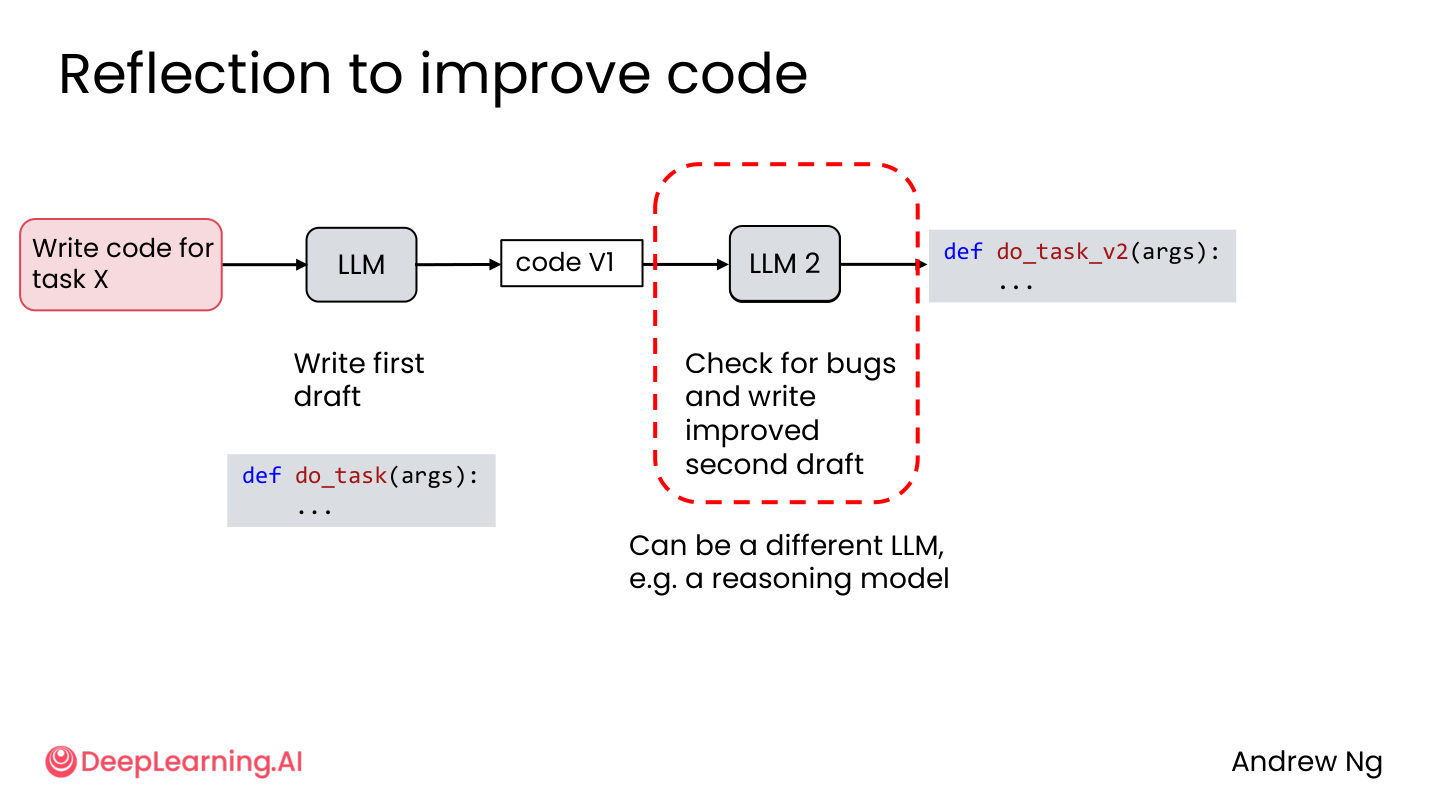
过程:
- LLM 写第一版代码
- 另一个 LLM(或同一个)检查 bug
- 写出改进后的第二版
💡 小白注释:就像程序员写完代码后让同事 code review。第一版代码总有 bug,有人帮你看一眼,质量高很多。
2.3 Reflection with External Feedback
Reflection 不一定只靠 LLM 自己检查,还可以接入外部反馈:
- 代码执行结果(跑一下看报不报错)
- 单元测试
- SQL 执行结果
- 图表视觉检查
- 字数统计
- 规则校验
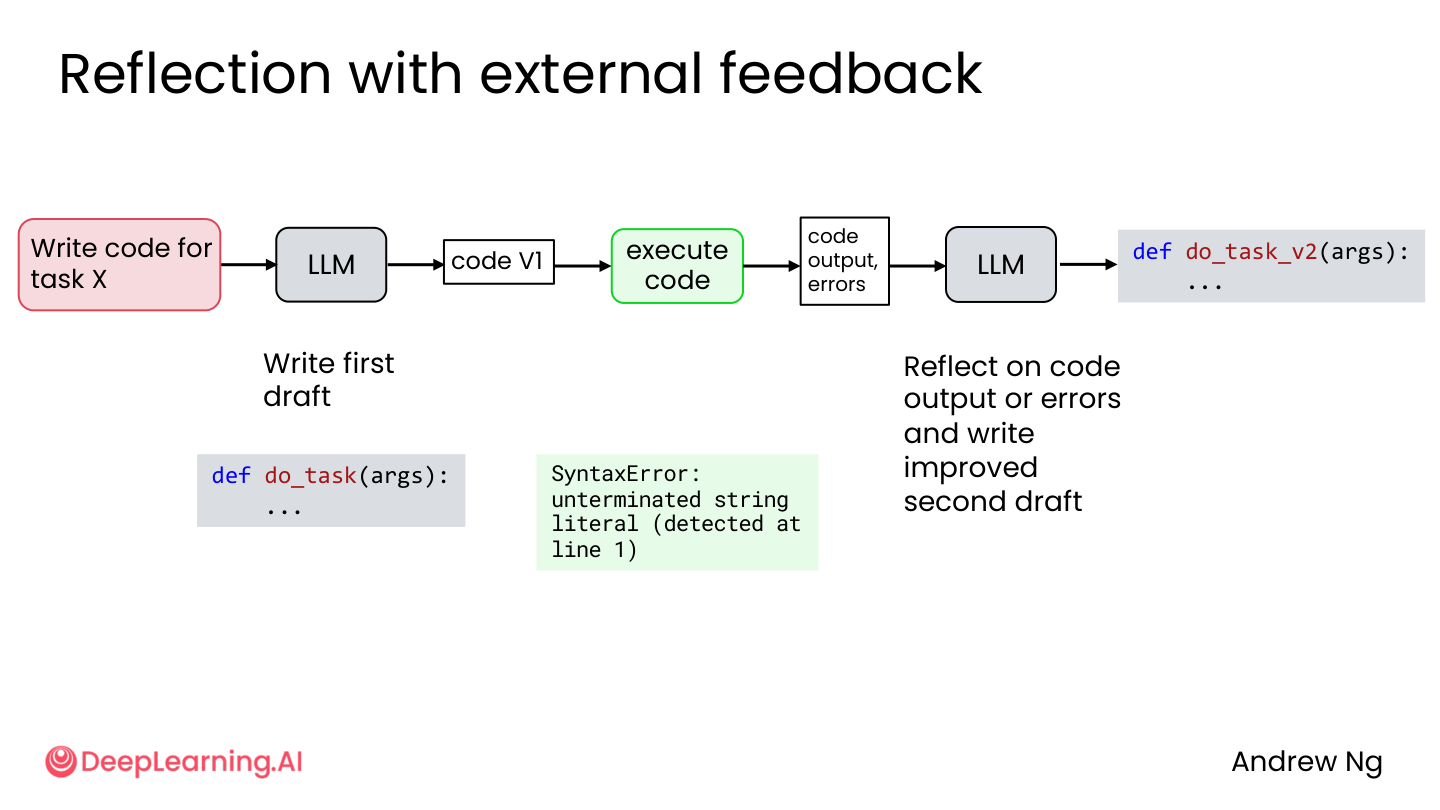
💡 小白注释:LLM 自己检查就像学生自查作业,容易”灯下黑”。让代码实际跑一下、让测试用例过一遍,就是”对答案”——错了就是错了,没法嘴硬。
2.4 为什么不是直接生成更好?
研究表明,Reflection 在各种任务上 consistently 优于直接生成。
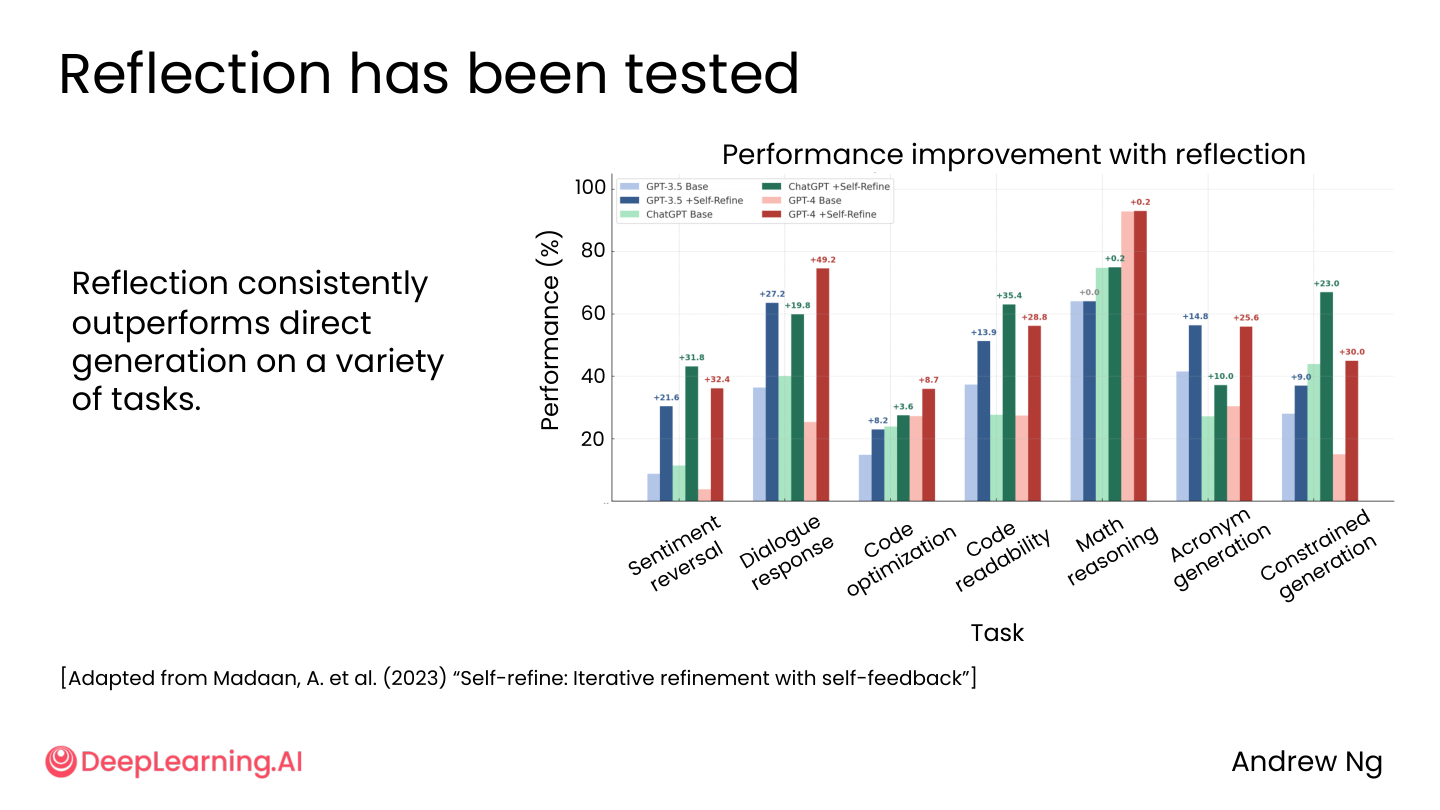
适用任务包括:情感反转、对话回复、代码优化、代码可读性、数学推理、缩写生成、受约束生成……
💡 小白注释:论文出处《Self-refine: Iterative refinement with self-feedback》(Madaan et al. 2023)。简单说——”写两遍”比”写一遍”好,这不是直觉,是有数据支撑的结论。
2.5 Reflection 适合什么任务
特别适合那些”有明确检查标准“的任务:
| 任务 | 检查什么 |
|---|---|
| HTML / 代码 | 语法对不对、能不能跑 |
| 邮件 / 文案 | 语气、事实、日期、承诺 |
| 图表 | 标题、标签、可读性 |
| 域名 | 有没有负面含义、好不好念 |
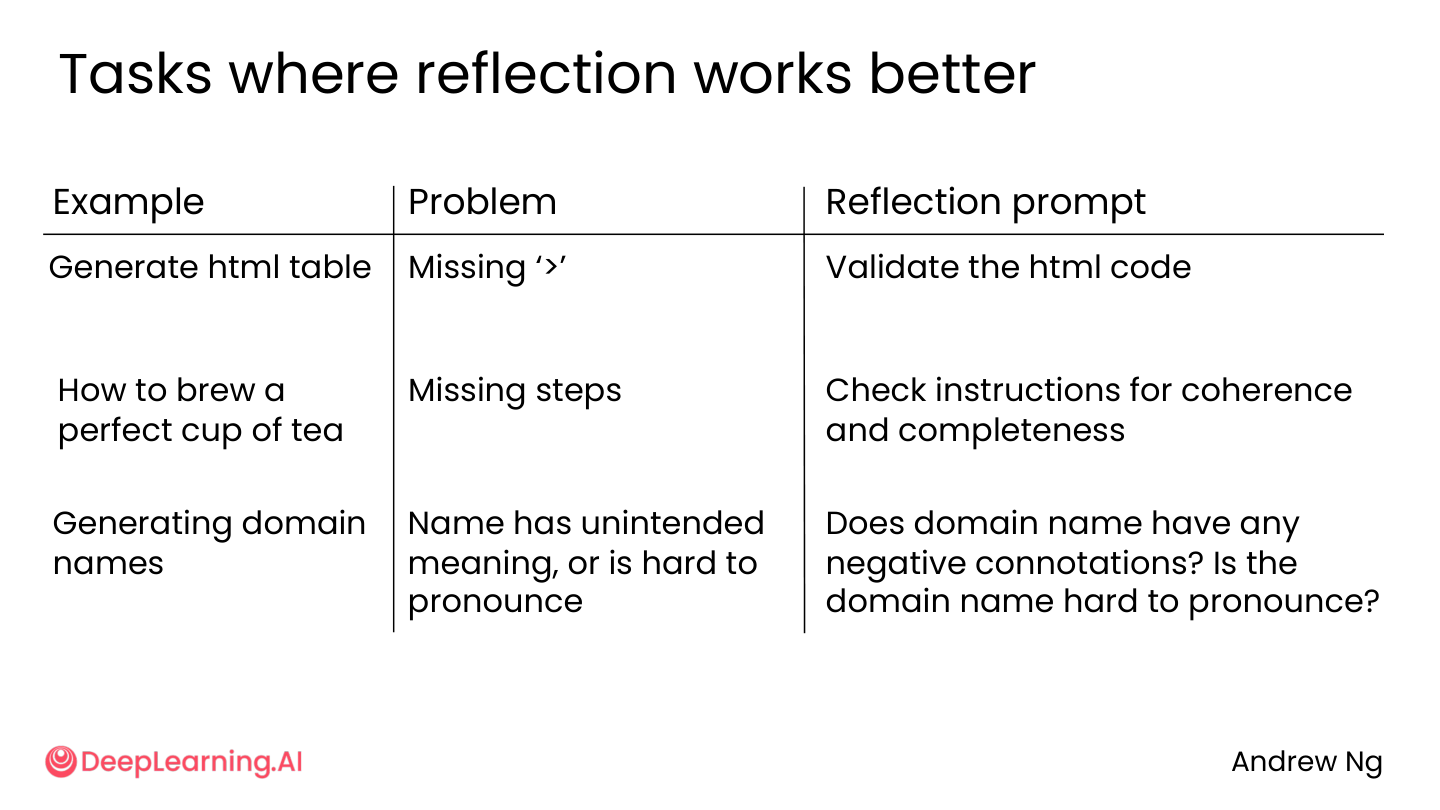
💡 小白注释:Reflection 不是万能药。如果任务连”好不好的标准”都没有(比如”写一首感人的诗”),那 Reflection 效果有限。但如果标准明确(”HTML 不能有语法错误”),Reflection 就能派上大用场。
2.6 写好 Reflection Prompt 的关键
不要说:
1
Improve it
要说:
1
2
3
Review the first draft.
Check tone, facts, dates, promises.
Then write the next draft.
关键要素:
- 明确指示审查动作
- 指定检查标准
- 审查完再输出改进版

💡 小白注释:就像你给下属改稿,说”改好一点”他不知道怎么改;说”检查第三段的数据来源,确认日期没写错,把语气改正式一点”,他就知道怎么做了。AI 也一样,prompt 越具体,Reflection 效果越好。
2.7 案例:图表生成工作流
任务:用 coffee_sales.csv 画一张对比 2024 和 2025 Q1 销量的图。
Agentic 流程:
- LLM 写 V1 代码 → 执行 → 出图
- LLM 审查图表(可读性、清晰度、完整性)→ 修改代码
- 执行 V2 代码 → 出改进后的图
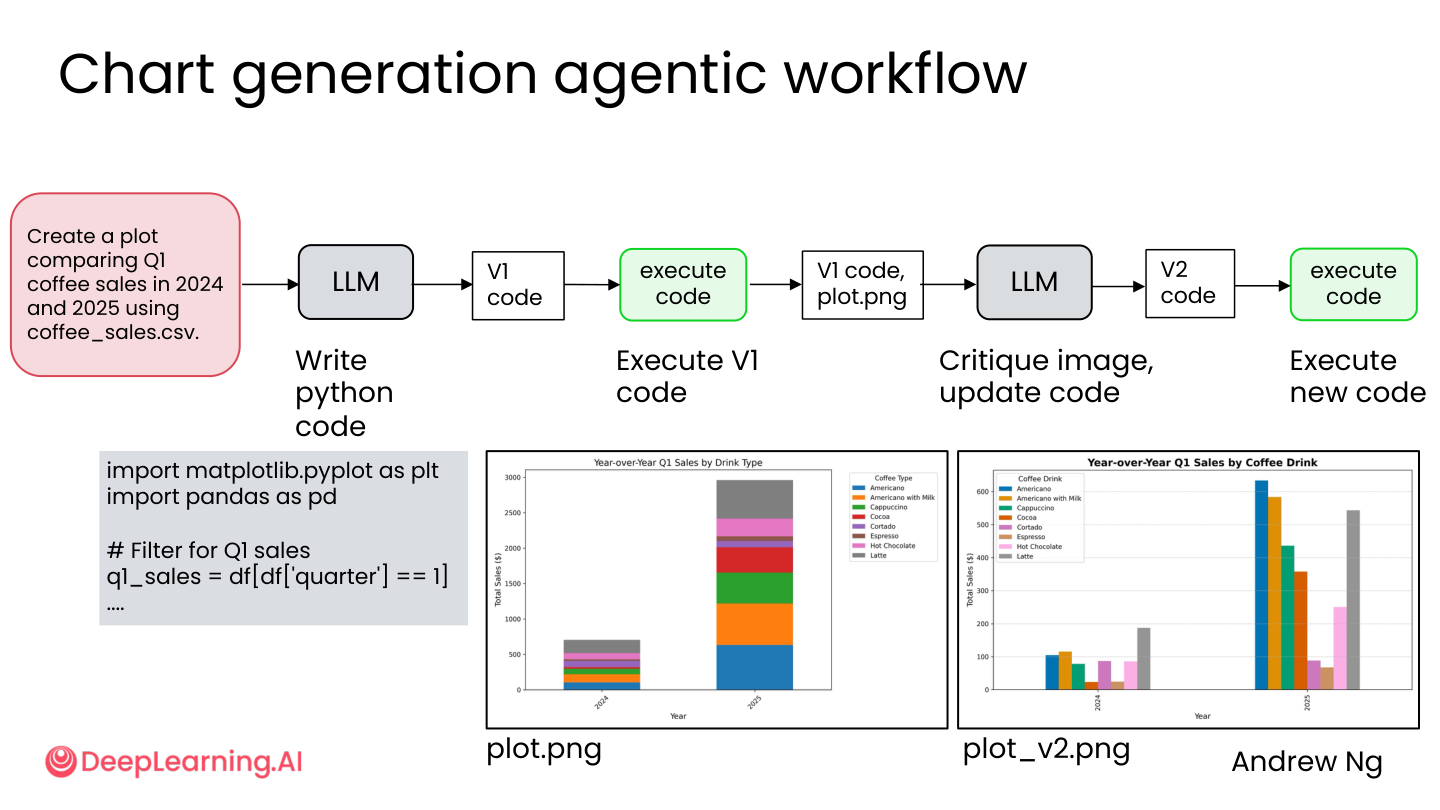
💡 小白注释:第一版图可能坐标轴没标签、颜色看不清、少了图例。Reflection 就是让 AI 自己看自己的图,发现问题再改。就像设计师做完海报自己先看一遍——”这字太小了,换大点”。
2.8 用不同的 LLM 做 Reflection
代码生成用一个 LLM,代码审查用另一个 LLM(比如更强的推理模型)。

💡 小白注释:就像写文章让 A 写、让 B 审。B 可能更擅长挑毛病,分工合作效果更好。
M3:Tool Use
3.1 Tool Use 是什么
Tool Use 的核心是:让 LLM 不只是会说,还能请求外部工具去执行。
- LLM 是”脑”
- 工具是”手脚”
3.2 最简单的例子:查时间
没有工具时,模型不知道当前时间:
1
2
User: 现在几点?
LLM: 抱歉,我无法获取当前时间。
有工具后:
1
2
3
User: 现在几点?
LLM: → 调用 get_current_time() → 返回 15:20:45
LLM: 现在是下午 3 点 20 分。

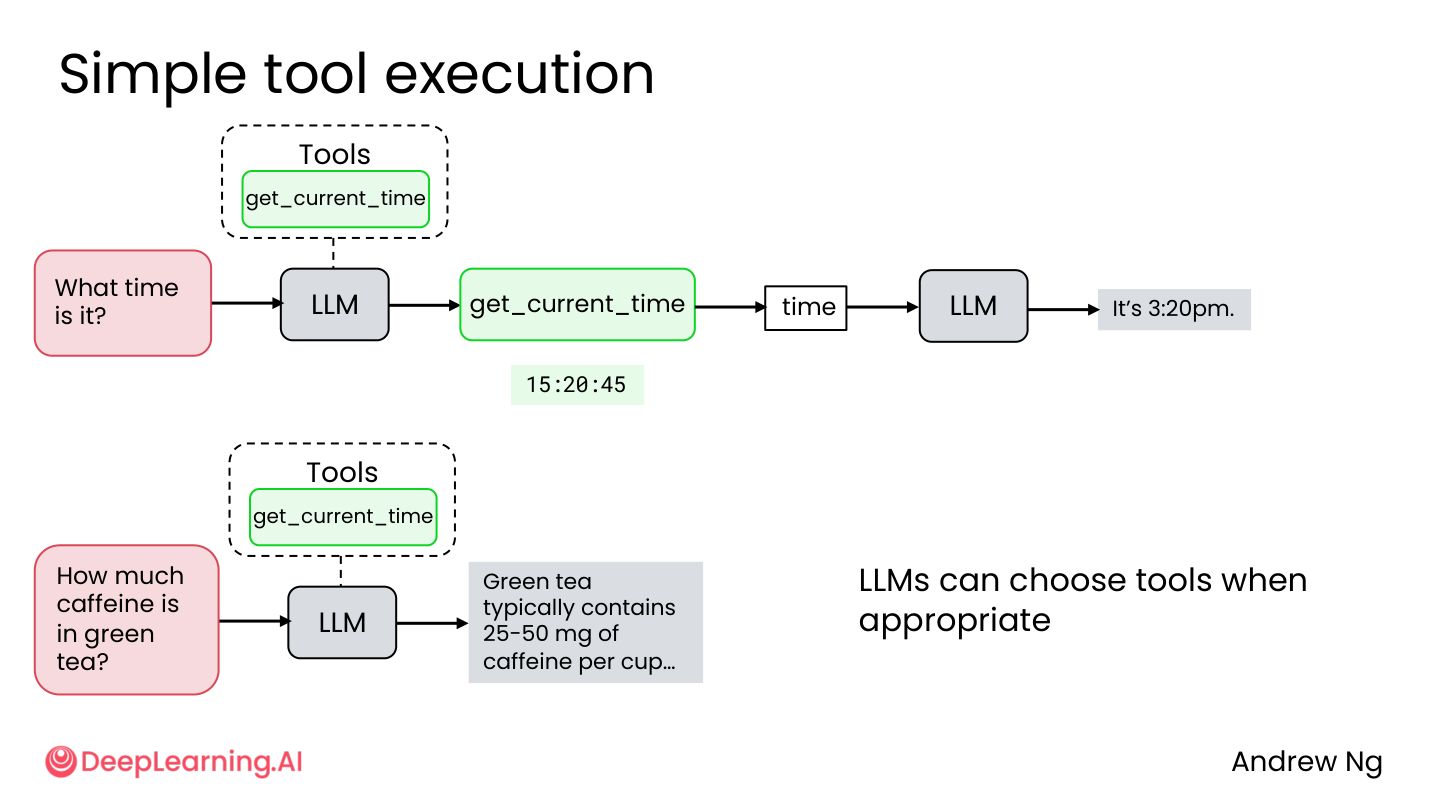
💡 小白注释:没有工具的 AI 就像个关在房间里的天才——脑子很好使,但不知道外面现在几点、今天天气如何、数据库里有多少客户。给了工具,就相当于给了它一部手机、一把钥匙、一张门禁卡,能出去查信息、办事了。
3.3 更多工具示例
| 用户问题 | 调用的工具 |
|---|---|
| “Mountain View 附近有什么意大利餐厅?” | web_search(query="...") |
| “500 美元存 10 年,年利率 5%,最后有多少?” | interest_calc(...) 或直接 eval(...) |
| “买了白色太阳镜的客户有哪些?” | query_database(table="sales", product="sunglasses", color="white") |

💡 小白注释:AI 看到问题后,自己判断需要用什么工具。就像你问朋友”附近有啥好吃的?”,他自然拿起手机打开点评 App——不用你告诉他”请使用美团搜索”。
3.4 多工具协作
复杂任务需要多个工具串联:
任务:”找一下我周四的空闲时间,然后和 Alice 约个会。”
流程:
- LLM 调用
check_calendar→ 发现周四 3pm、4pm、6pm 有空 - LLM 决定选 3pm
- LLM 调用
make_appointment→ 预约成功
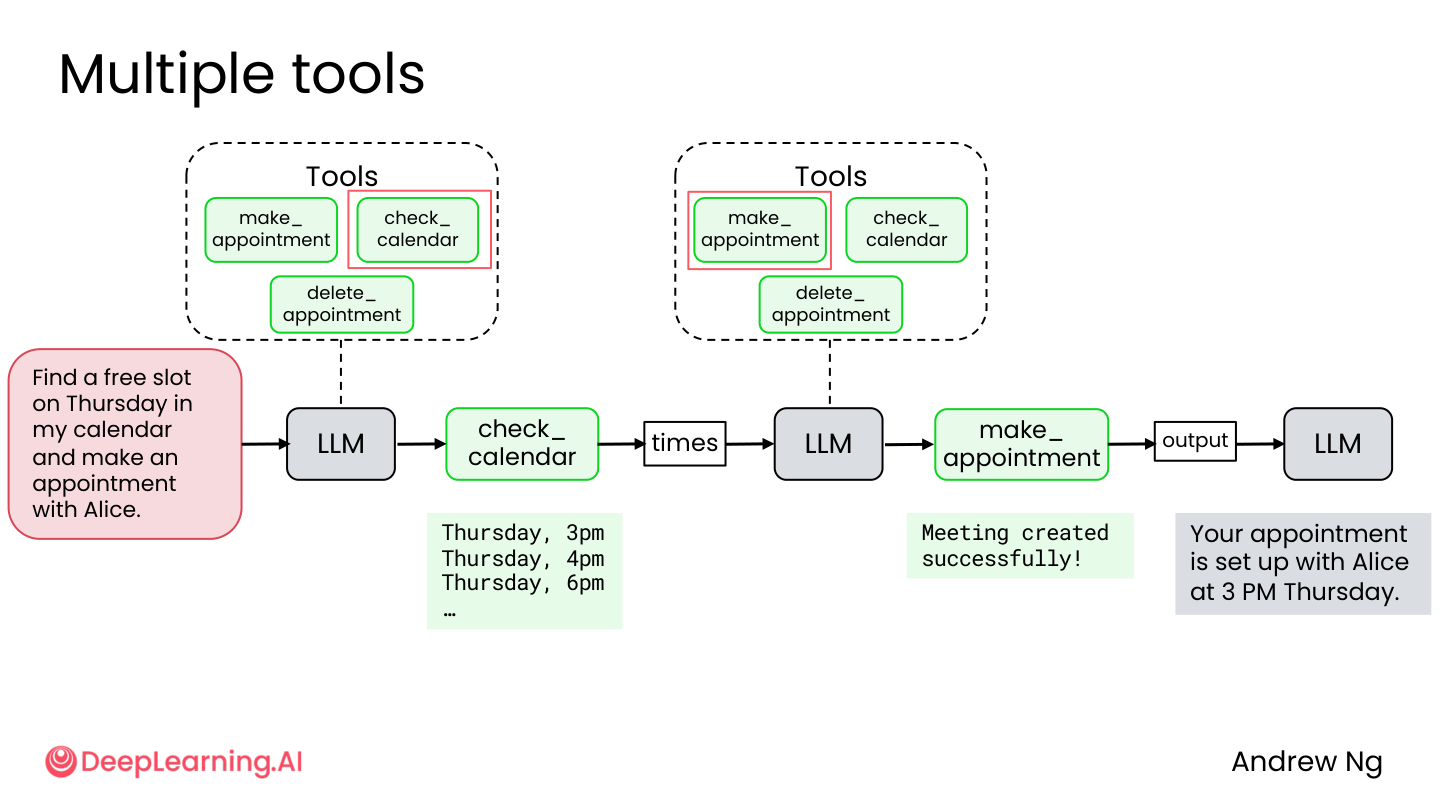
💡 小白注释:AI 不是一次把所有工具都调用完,而是根据上一步的结果决定下一步做什么。查到 3pm 有空,才决定约 3pm;如果 3pm 被占了,就会约 4pm。这种”看一步走一步”是 Agentic AI 的核心特征。
3.5 工具本质上就是代码
课件里的结论很直接:工具就是代码。
1
2
3
4
5
from datetime import datetime
def get_current_time():
"""Returns the current time as a string"""
return datetime.now().strftime("%H:%M:%S")

💡 小白注释:一个工具就是一个 Python 函数。你给 AI 一堆函数,告诉它每个函数是干嘛的,AI 自己决定什么时候调用哪个。这和你写程序时调用库函数没什么区别——只不过调用者从”你”变成了”AI”。
3.6 工具语法与 aisuite
现代框架(如 aisuite)可以自动把函数描述传给 LLM:
1
2
3
4
5
6
7
8
9
import aisuite as ai
client = ai.Client()
response = client.chat.completions.create(
model="openai:gpt-4o",
messages=messages,
tools=[get_current_time], # 直接把函数传进去
max_turns=5
)
框架会自动生成 JSON Schema 告诉模型:
- 工具叫什么名字
- 工具做什么
- 需要什么参数
- 参数格式是什么


💡 小白注释:JSON Schema 就是一份”工具说明书”。模型看到说明书后就知道:哦,有个工具叫 get_current_time,不需要参数,用来查当前时间。用户问时间的时候我应该调用它。
3.7 代码执行:当工具不够用
有些问题不适合做成固定工具,比如:
- “13.2 加 18.9 等于多少?”
- “2 的平方根是多少?”
为每个数学运算做一个工具太麻烦了。更好的做法:让 AI 直接写 Python 代码执行。
1
2
3
4
<execute_python>
import math
print(math.sqrt(2))
</execute_python>
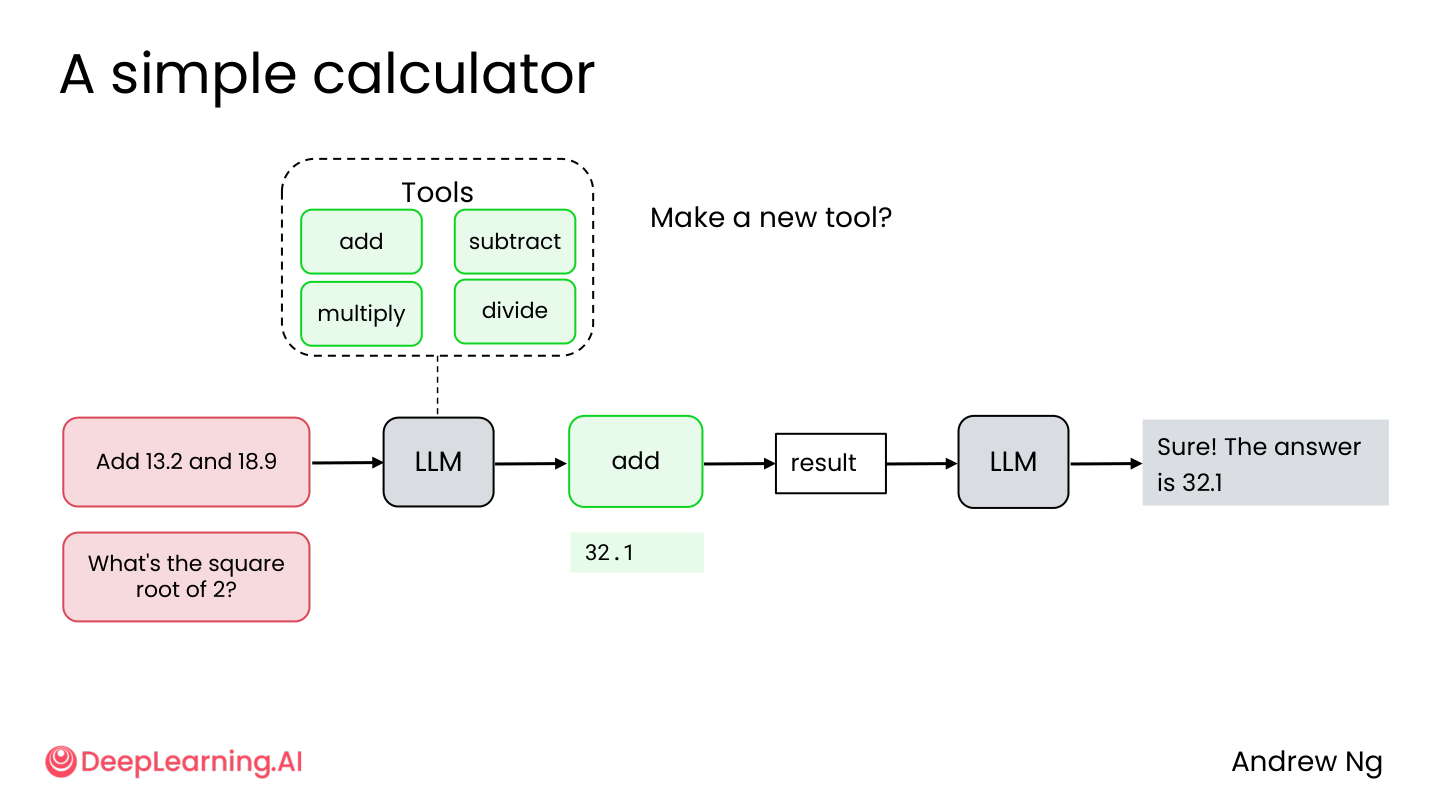
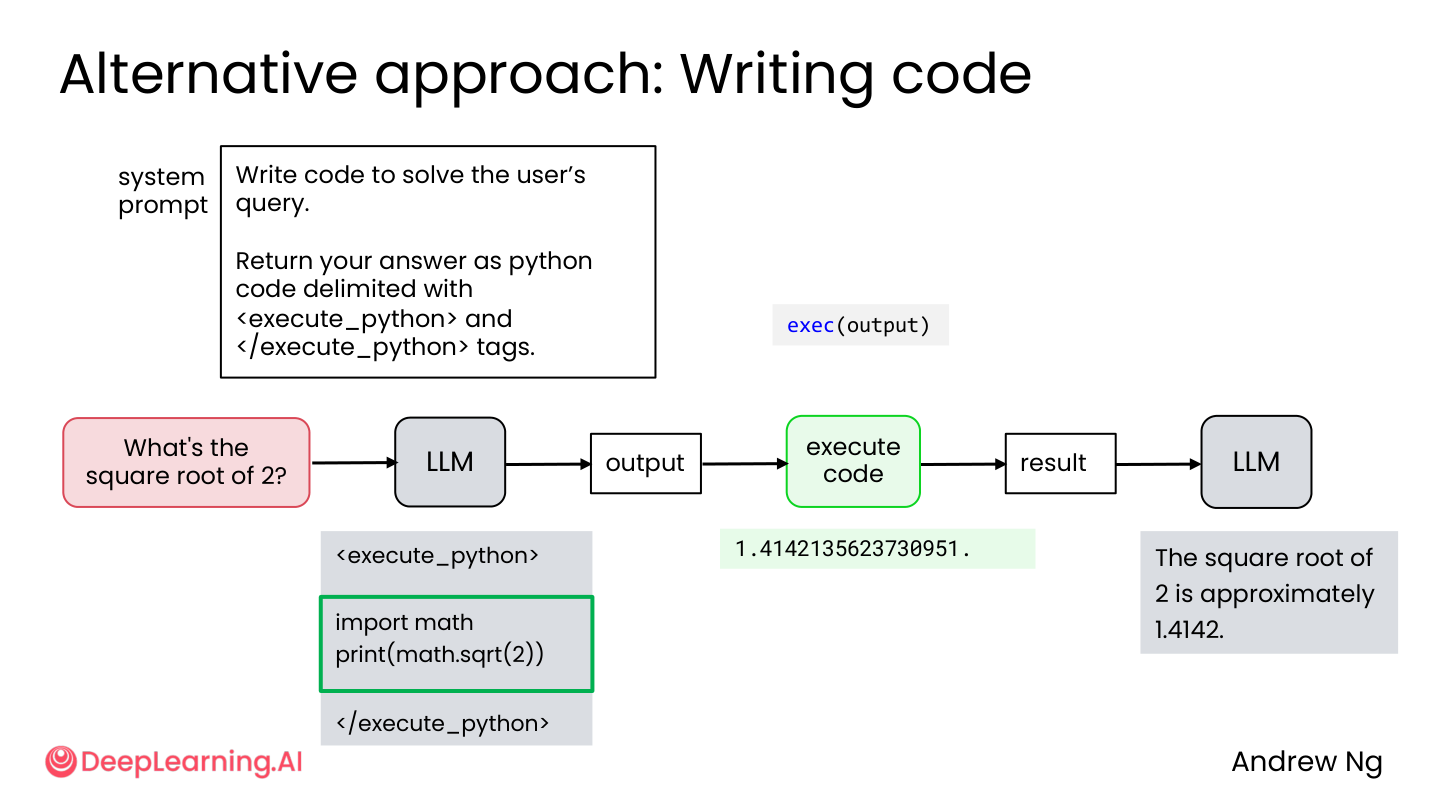
💡 小白注释:与其给 AI 准备一百个计算器工具(加、减、乘、除、开方、对数……),不如给它一个 Python 解释器。需要什么计算自己写代码,比预制工具灵活一万倍。
3.8 安全问题:沙箱
代码执行很强,但也危险——AI 可能写出删除文件的代码。
必须有:
- Sandbox(沙箱)隔离运行环境
- 权限控制
- 时间限制(防止死循环)
- 文件访问限制
- 网络访问限制

💡 小白注释:沙箱就像给 AI 一个”透明实验室”——它可以在里面做实验、做计算,但没法碰到你电脑里的重要文件。就像化学课上的通风橱,有害气体排出去,不会污染教室。
3.9 MCP:工具接入的标准化
问题:每个应用都要自己对接 Slack、GitHub、Google Drive……m × n 的复杂度。
MCP(Model Context Protocol)的解法:
- 所有工具统一接到 MCP Server
- 每个应用只需要对接 MCP Server
- 复杂度从 m × n 降到 m + n
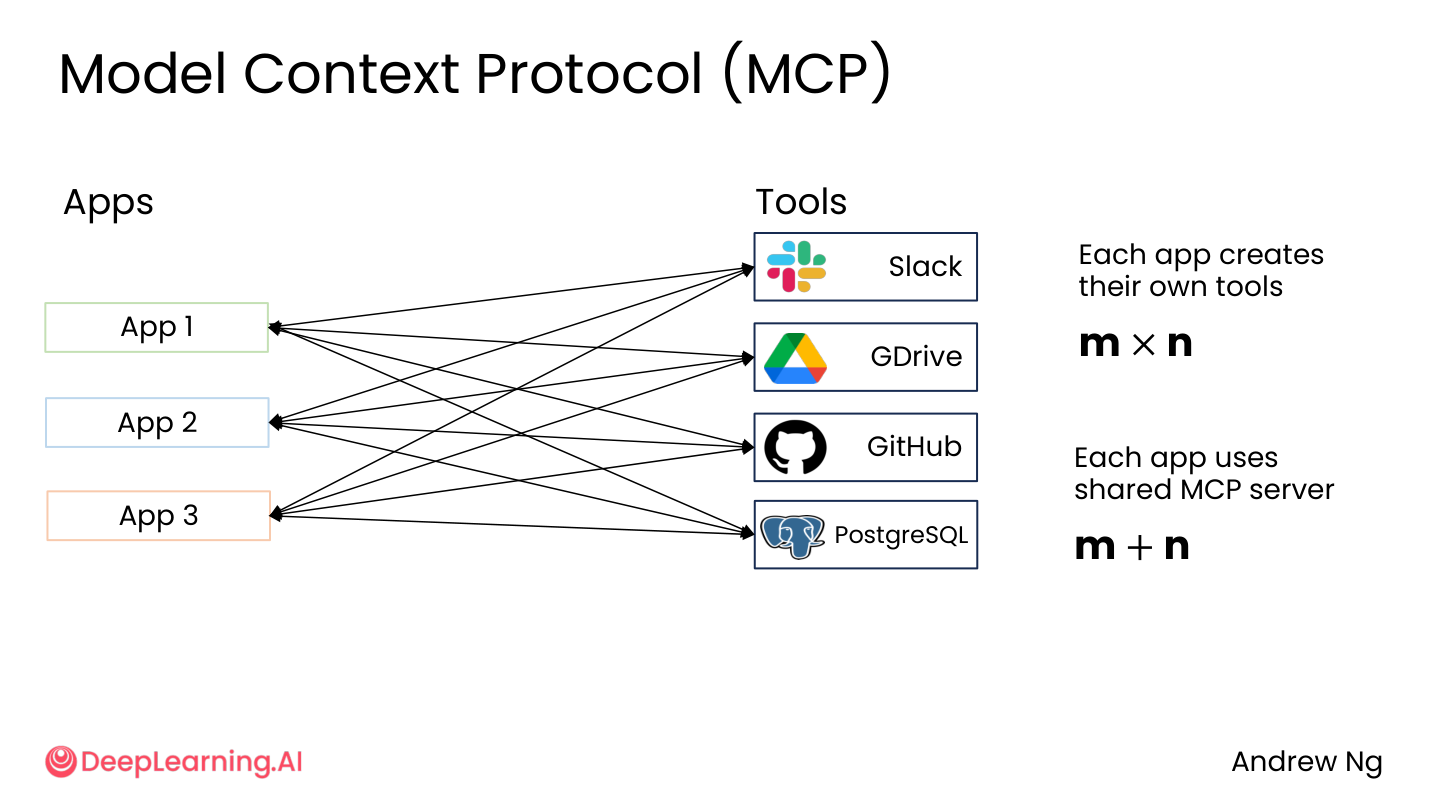
💡 小白注释:没有 MCP 时,3 个应用要分别对接 4 个工具,一共 12 根线。有了 MCP,3 个应用各接 1 个 MCP Server,4 个工具也各接 1 个 MCP Server,一共 7 根线。线少了,维护简单,换工具也不用改应用代码。
M1–M3 串起来看
三节课的完整逻辑:
1
2
3
4
5
6
7
M1:Workflow & Decomposition
↓
M2:Reflection & Revision
↓
M3:Tool Use & Execution
↓
更可控、更强的 Agentic AI
| 课程 | 解决什么 | 核心 takeaway |
|---|---|---|
| M1 | 任务怎么拆、什么时候该分步 | 不要一次性生成,要拆成多步可控流程 |
| M2 | 生成后怎么检查、怎么把质量变好 | 写完后检查一遍再改,比直接写更好 |
| M3 | 怎么让模型真的”做事” | 给 AI 工具和代码执行能力,它就能查信息、算数据、调 API |
💡 小白注释:M1 教你搭骨架,M2 教你打磨质量,M3 教你长出手脚。三节课合起来,你就有了一个能思考、能检查、能动手的 AI 系统的基础框架。
附录:全部幻灯片索引
M1 (39 页)
| 页码 | 内容 |
|---|---|
| 1 | 封面 |
| 2 | 目录 |
| 3 | Non-agentic vs Agentic workflow 对比 |
| 4 | Agentic workflow 定义 + 论文例子 |
| 5 | Degrees of Agenticness |
| 6-8 | 自主程度连续谱(低自主 → 高自主) |
| 9 | Benefits |
| 10 | HumanEval benchmark 性能对比 |
| 11 | Parallelization 并行化 |
| 12 | Modular 模块化 |
| 13 | Key benefits 总结 |
| 14-39 | 更多案例与细节 |
M2 (27 页)
| 页码 | 内容 |
|---|---|
| 1 | 封面 |
| 2 | 目录 |
| 3 | Reflection 人类例子(写邮件 V1→V2) |
| 4 | Reflection 改进代码 |
| 5 | Reflection with external feedback |
| 6 | Why not direct generation? |
| 7-9 | Direct generation vs Zero/One/Few-shot |
| 10 | Reflection 性能提升数据 |
| 11 | Tasks where reflection works better |
| 12 | Tips for writing reflection prompts |
| 13-16 | Chart generation workflow |
| 17 | Evaluating impact of reflection |
| 18-27 | 更多细节 |
M3 (24 页)
| 页码 | 内容 |
|---|---|
| 1 | 封面 |
| 2 | 目录 |
| 3-4 | Simple tool execution(查时间) |
| 5 | 工具示例(搜索、计算、数据库) |
| 6 | Multiple tools(查日历 + 预约) |
| 7 | Creating a tool |
| 8 | Your code as a tool |
| 9-10 | Prompting LLM to use tools |
| 11 | Tool syntax |
| 12-14 | aisuite + JSON Schema |
| 15 | Code execution |
| 16-17 | Calculator / Writing code |
| 18 | Reflection with external feedback(代码执行) |
| 19 | Secure code execution / Sandbox |
| 20 | MCP |
| 21-22 | Model Context Protocol |
| 23-24 | End |