Agentic AI 学习笔记:M4 评估与错误分析
整理 Andrew Ng Agentic AI 课程 M4 核心内容:如何建立评估体系、进行错误分析、优化延迟与成本。
# M4: Practical Tips for Building Agentic AI
来源: agentic_workflows_M4_learner.pdf 讲师: Andrew Ng
💡 小白注释:这堂课讲的是”怎么搭一个靠谱的 AI 自动干活系统”。想象你在开一家全自动奶茶店——AI 负责接单、加料、摇杯。这课教你怎么发现 AI 哪里做不好、怎么打分、怎么改、怎么省钱。全文用 💡 标记的部分都是给新手看的通俗解释。
目录
- 一、评估 Evaluations
- 二、错误分析与优先级 Error Analysis
- 三、组件级评估 Component-level Evaluations
- 四、如何解决问题
- 五、延迟与成本优化
- 六、开发流程总结
一、评估 Evaluations
1.1 为什么需要评估
构建 Agentic AI 系统时,评估是驱动开发流程的核心。通过评估可以:
- 发现系统表现不佳的地方
- 用约 20 个示例的小型评估集跟踪进展
- 监控修改(如新提示、新算法)后指标是否改善
💡 小白注释:就像老师给学生出考卷。没有考卷,你不知道学生到底学会了没有;没有评估,你改了 AI 的提示词或换了模型,也不知道是变好了还是变坏了。考卷不用多,20 道题就够摸底了。

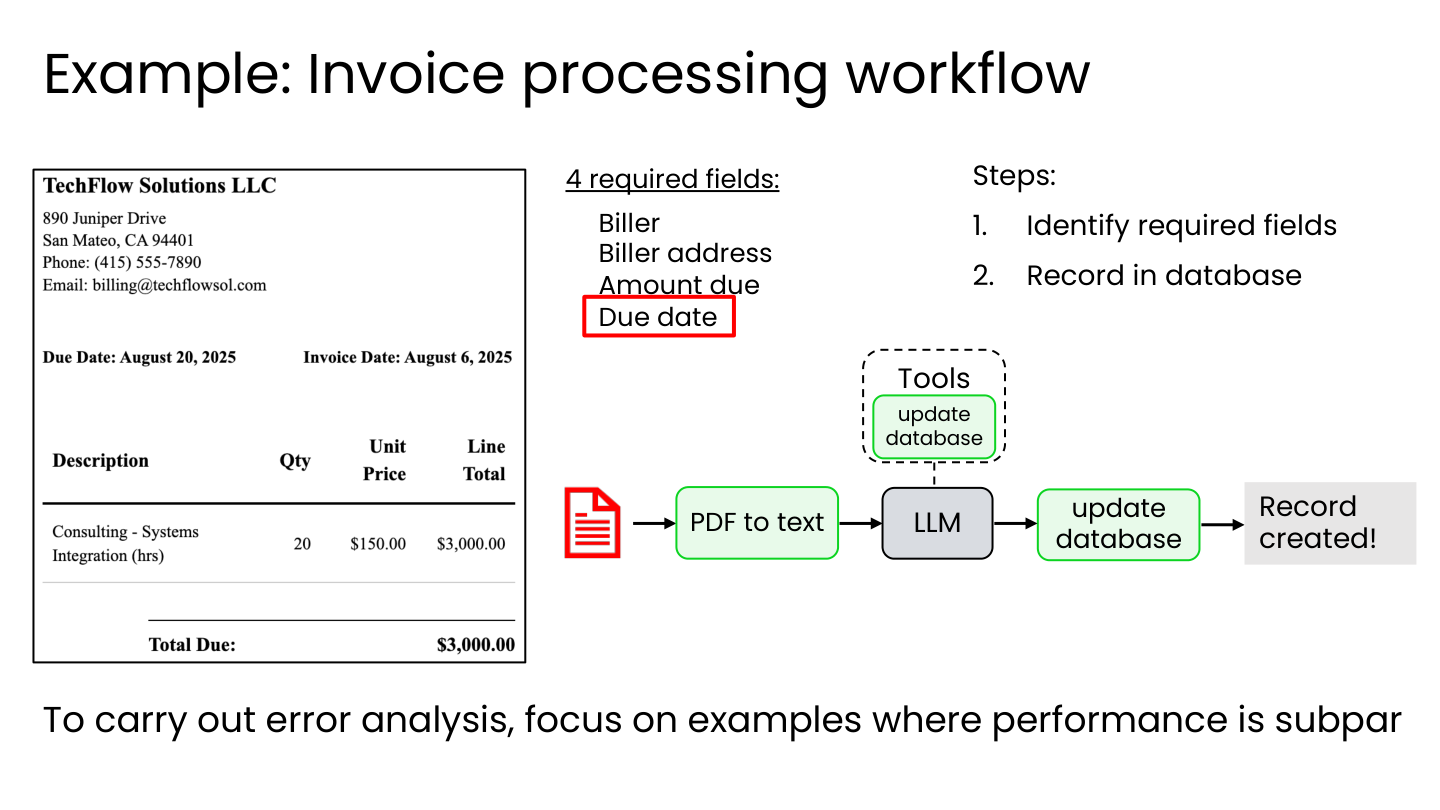
1.2 案例一:发票处理工作流
场景: 从 PDF 发票中提取 4 个必填字段(付款方、付款方地址、应付金额、到期日)。
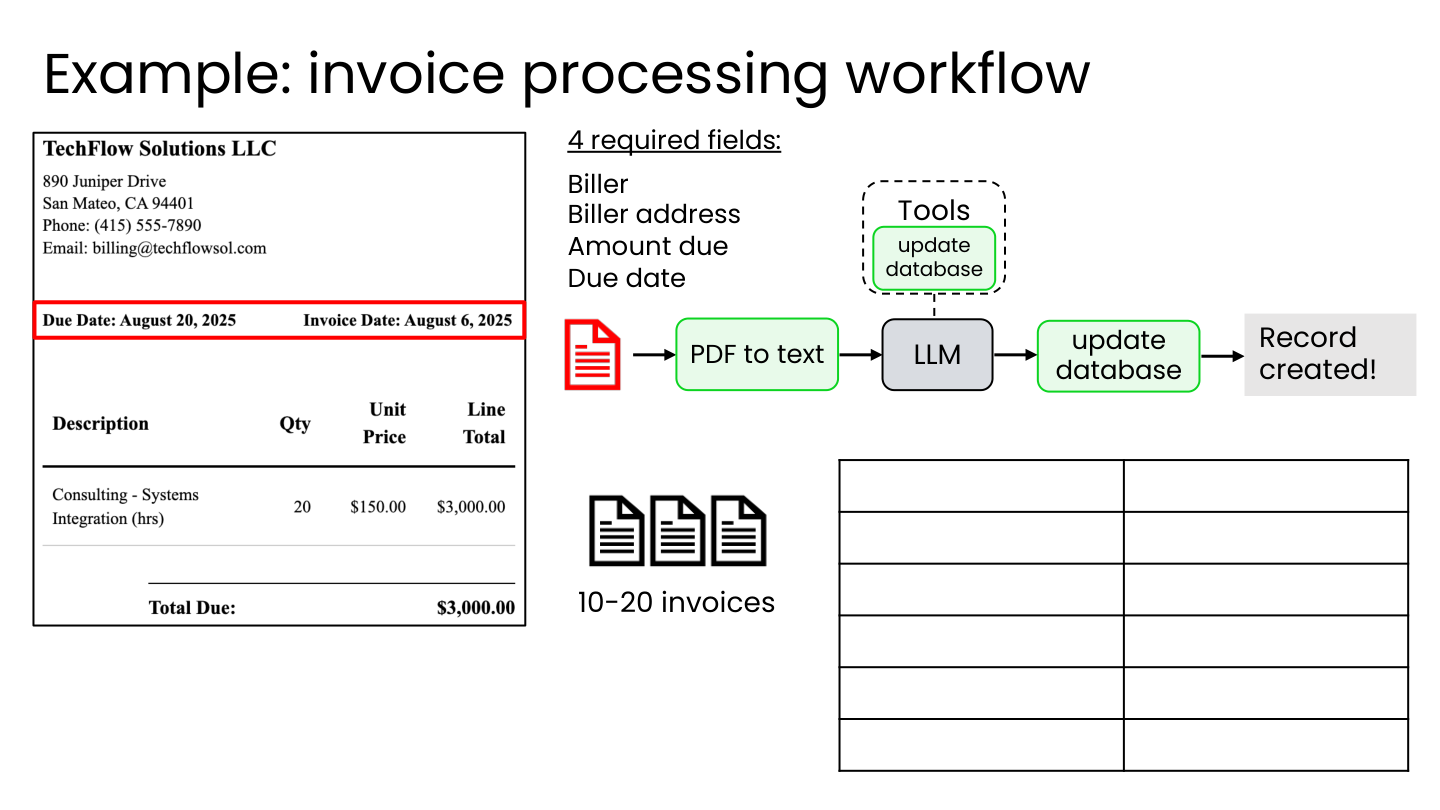
💡 小白注释:你雇了一个 AI 员工”小张”,他的工作是看 PDF 发票、填表格。需要提取 4 项:谁开的票、地址、金额、到期日。结果发现——到期日经常搞错,”August 20, 2025” 被写成了 “2025/08/02”。
问题: LLM 有时会搞混日期。
创建评估的方法:
- 手动从 10-20 张发票中提取到期日作为标准答案
- 在提示中指定数据输出格式(如
YYYY/MM/DD) - 用代码从 LLM 响应中提取日期
- 对比 LLM 结果与标准答案
1
2
3
4
date_pattern = r'\d{4}/\d{2}/\d{2}'
extracted_date = re.findall(date_pattern, llm_response)
if (extracted_date == actual_date):
num_correct += 1
💡 小白注释:这段代码的意思是:先用正则表达式从 AI 的回答里”捞出”日期,然后和”标准答案”对比,对了就加一分。20 张发票测下来,比如对了 15 题 → 正确率 75%。这就是 AI 的成绩单。

驱动开发流程:
- 构建系统并查看输出
- 发现不满意的行为(如日期提取错误)
- 建立小型评估集追踪改进
- 修改工作流后监控指标变化
💡 小白注释:这就是”用考卷驱动进步”。今天正确率 75%,你改了改提示词 → 再测 → 80% → 有进步!换了更贵的模型 → 再测 → 95% → 值!没有考卷,你就像蒙着眼睛开车,根本不知道改完好了还是坏了。

1.3 案例二:营销文案助手
场景: 生成符合长度规范的营销文案(如 Instagram 标题不超过 10 个词)。

💡 小白注释:AI 员工”小美”写 Instagram 文案,要求是标题不能超过 10 个字。结果她写出来的经常超标:11 个字、14 个字、17 个字……这活不难,但 AI 就是管不住自己的”字数”。
创建评估的方法:
- 创建 10-20 个测试任务
- 用代码测量输出词数
- 对比生成文本长度与限制
1
2
3
word_count = len(text.split())
if (word_count <= 10):
num_correct += 1
💡 小白注释:这段代码更简单:把 AI 写的文案按空格拆开数词数,超过 10 个就不及格。20 个测试题跑一遍,算一下合格率。

1.4 案例三:研究代理
场景: 研究代理撰写主题文章,但有时会遗漏人类会提及的重要观点。
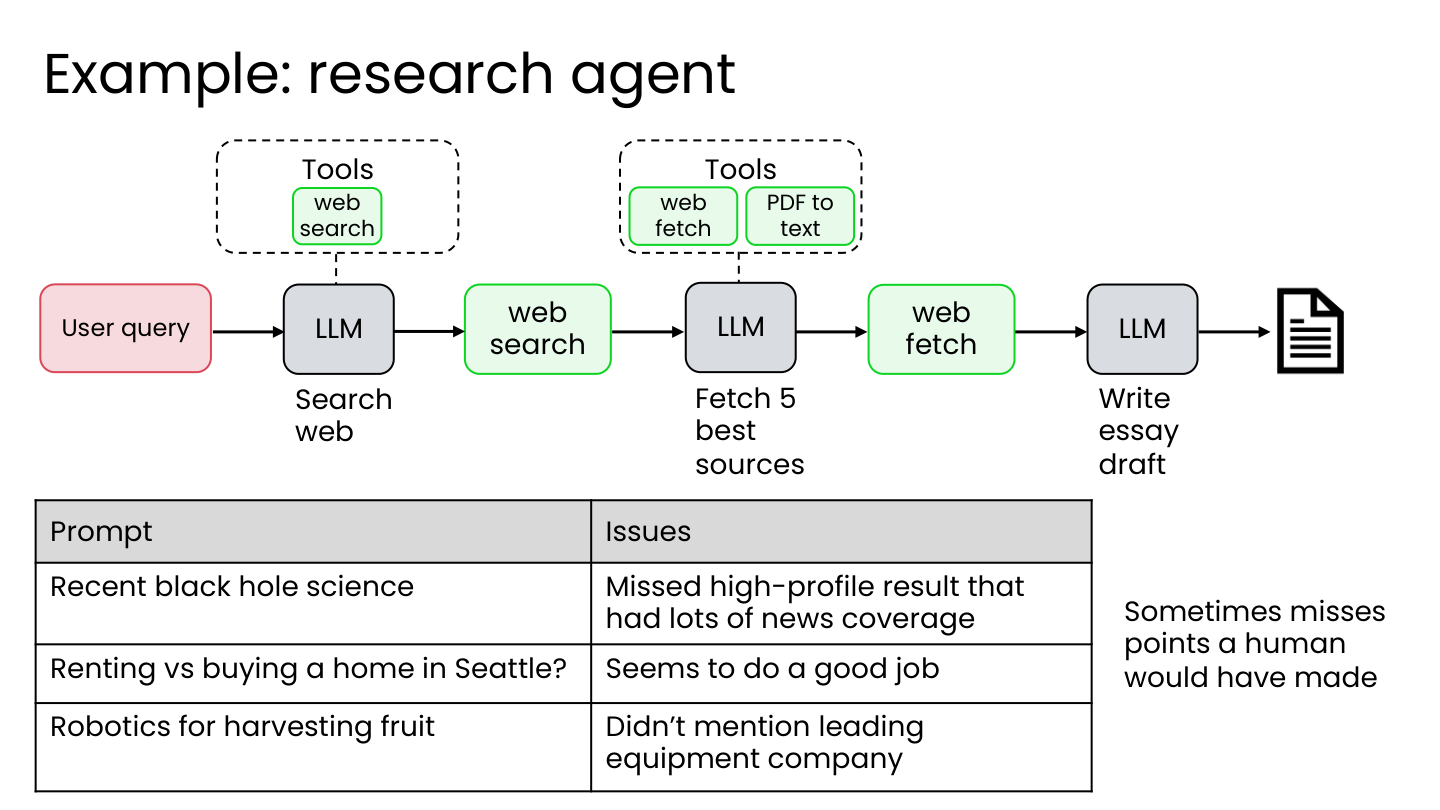
💡 小白注释:AI 研究员”小李”写文章,人类一看——这么重要的发现怎么没提?这种”写得好不好”很难用程序自动判断。怎么办?再雇一个 AI 当”阅卷老师”!
创建评估的方法(LLM-as-a-Judge):
- 为每个主题选择 3-5 个黄金标准讨论点
- 用 LLM 作为评判,统计提及了多少要点
- 为评估集中的每个提示获取分数
评判提示示例:
1
2
3
4
5
6
7
8
9
10
11
Determine how many of the 5 gold-standard talking points
are present in the provided essay.
Original Prompt: {original_prompt}
Essay to Evaluate: {essay_text}
Gold Standard Talking Points: {gold_standard_points}
Output Format:
Return a JSON object with two keys:
- score (a number between 0 and 5)
- explanation (a string listing present talking points)
💡 小白注释:你先作为人类专家,列出 5 个”这篇文章必须提到的关键点”(比如黑洞文章必须提”事件视界望远镜”)。然后把文章和这 5 个关键点一起喂给另一个 AI,让它打分:5 分满分,小李得了 2 分 → 不及格,回去重写。

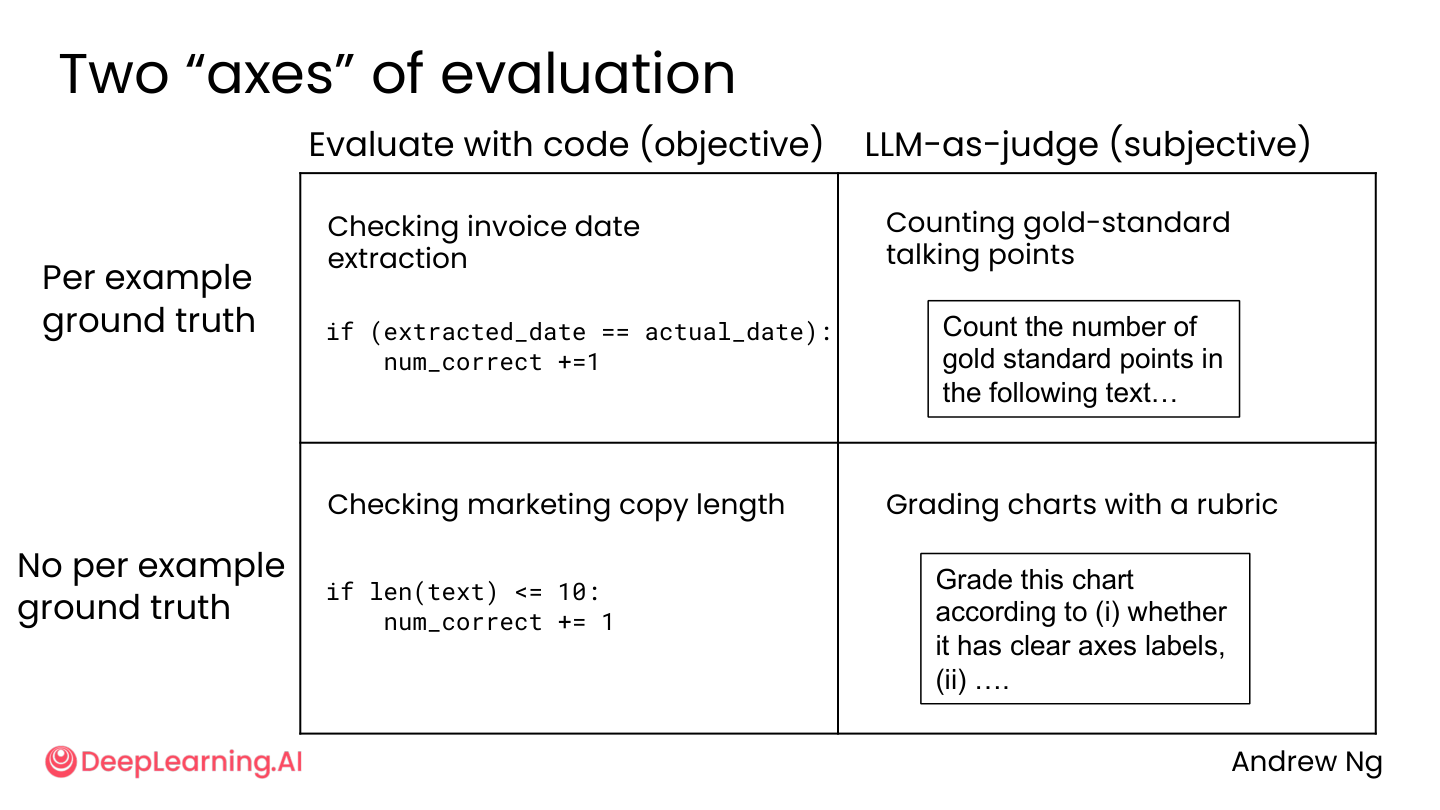
1.5 评估的两个维度
| 维度 | 类型 | 是否需要标准答案 | 示例 |
|---|---|---|---|
| 代码评估 | 客观 | 需要 | 发票日期提取、文案长度检查 |
| LLM-as-Judge | 主观 | 不需要 | 统计黄金标准要点、按评分标准给图表打分 |
💡 小白注释:两种考卷:一种是客观题(对就是对,错就是错,程序自动判卷),一种是主观题(没有唯一答案,需要”AI 阅卷老师”来评)。就像数学选择题 vs 语文作文。
1.6 设计端到端评估的技巧
- 先快速搭建: 初始评估可以粗糙,能快速开始最重要
- 持续改进: 当发现评估无法捕捉人类判断时,将其作为改进指标的机会
- 对标人类: 寻找性能比人类差的地方
💡 小白注释:刚开始的考卷可以很简陋,能跑就行。发现”AI 考了 90 分但写出来的东西人类一看还是烂”——这说明你的考卷出得不好,该升级考卷了。考卷本身也要不断迭代。

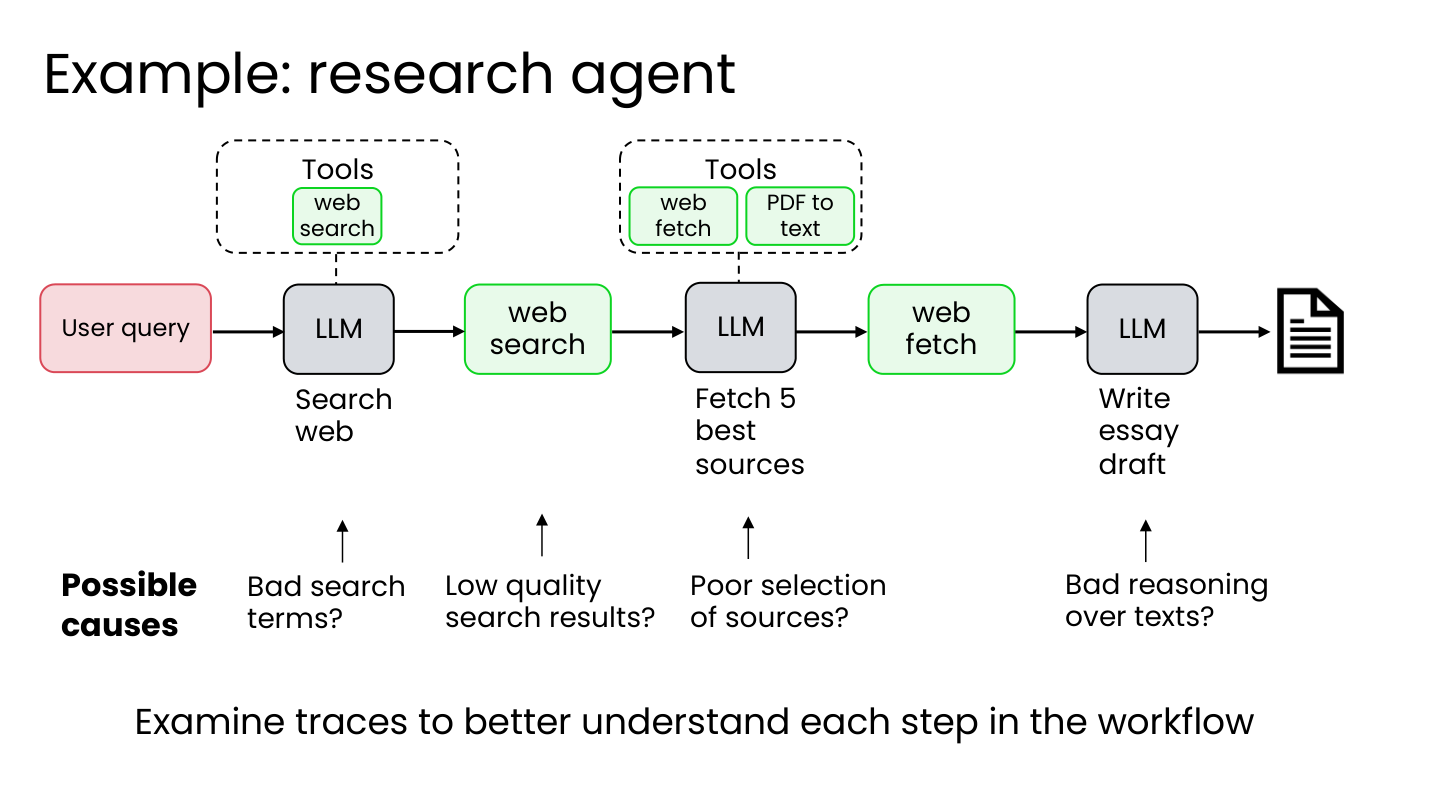
二、错误分析与优先级 Error Analysis
2.1 什么是错误分析
错误分析是指查看系统运行轨迹(traces),找出哪个组件表现不佳,导致最终输出质量差。
💡 小白注释:AI 搞砸了不要直接骂 AI,要翻”监控录像”看是哪一步出的问题。是搜索时关键词太烂?还是搜出来的结果质量差?或者读资料时理解错了?就像奶茶店客人投诉太甜,你要看是糖加多了,还是原料本身甜。

2.2 研究代理错误分析示例
观察到的错误模式: 有时会遗漏人类会提及的关键要点。
可能的原因:
- 搜索词不佳?
- 搜索结果质量低?
- 选择的来源不合适?
- 对文本的推理能力差?
💡 小白注释:小李写黑洞文章漏了大新闻,可能有四个”嫌疑人”:搜索关键词太泛、搜出来都是娱乐新闻、好文章被漏选了、或者读了但脑子没转过弯。
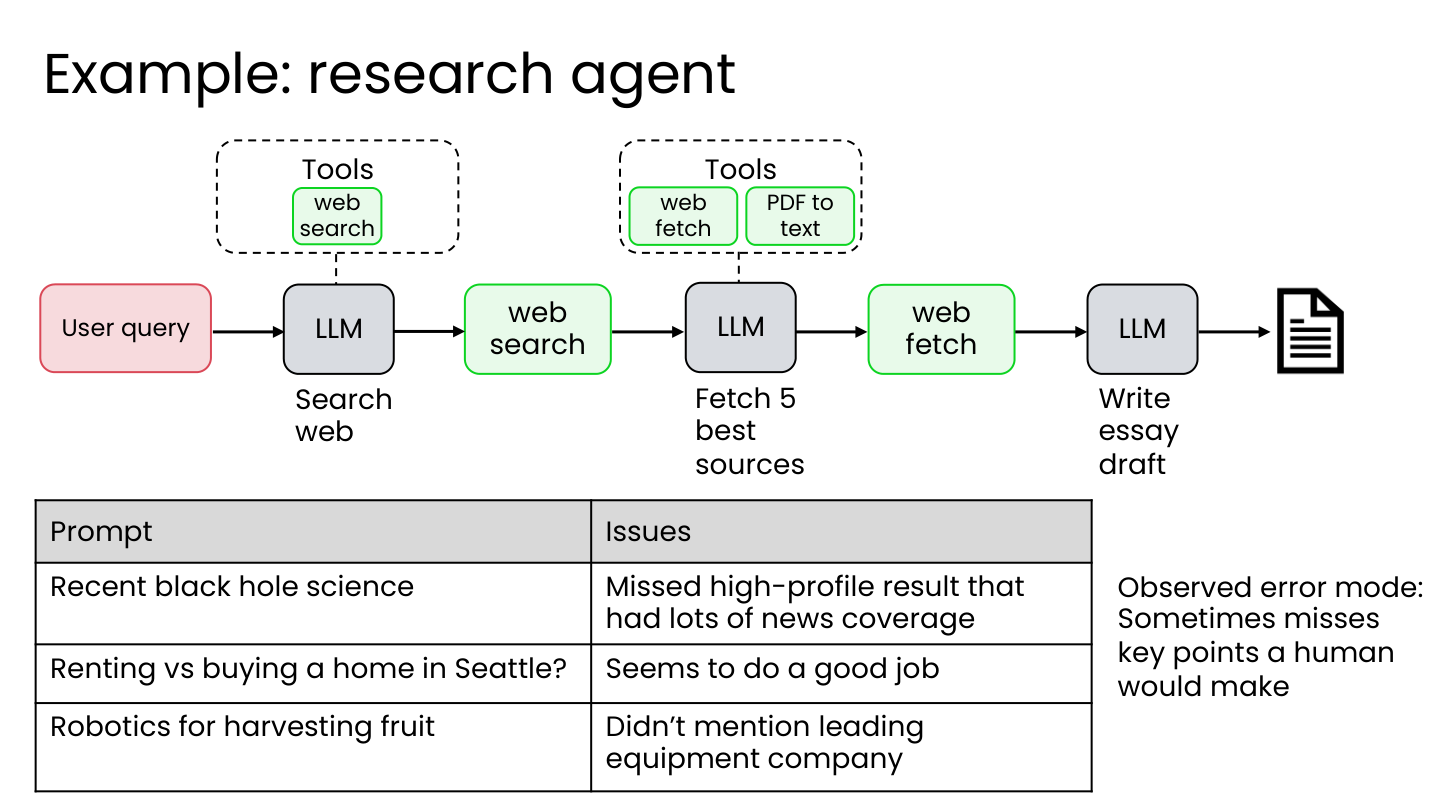
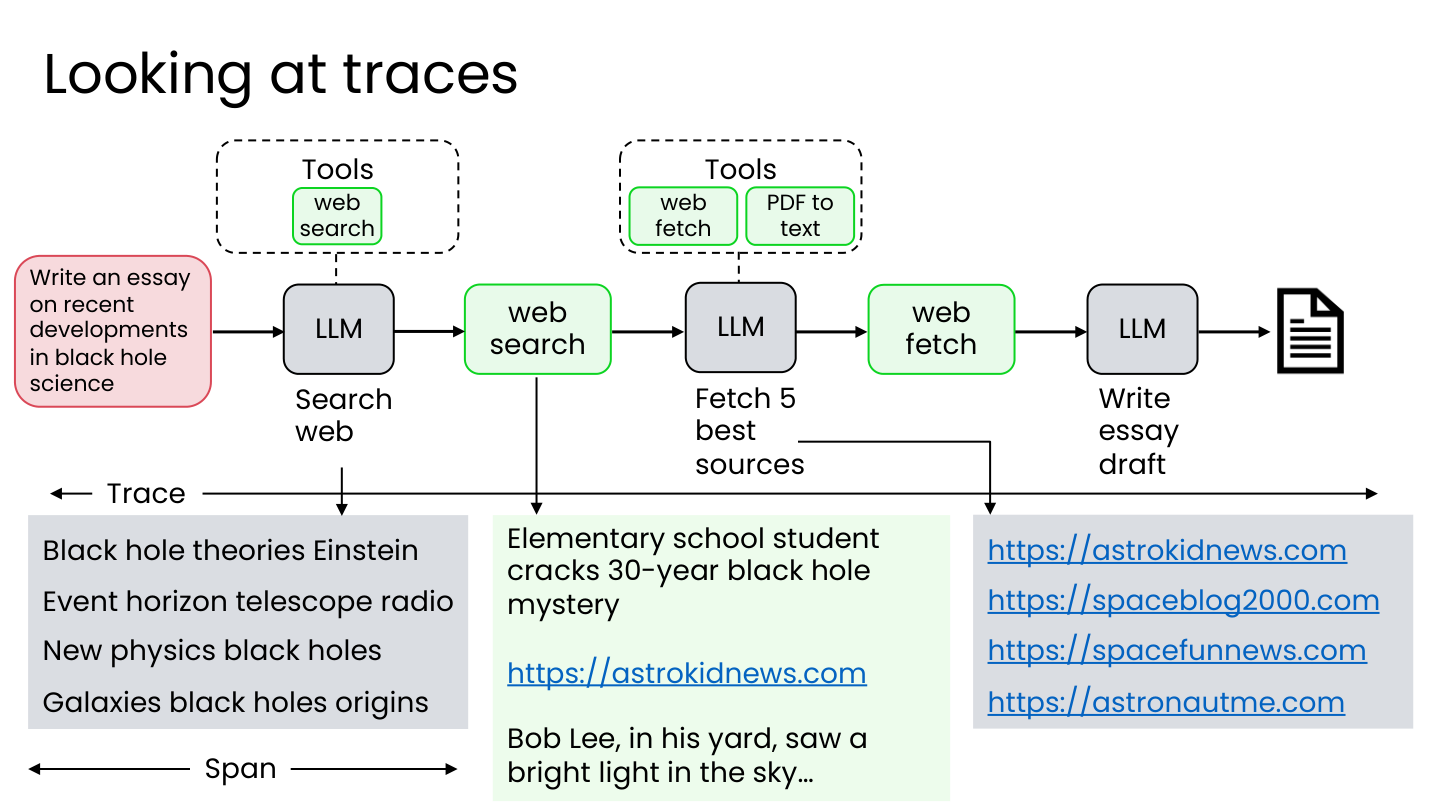
查看轨迹(Traces): 通过检查每个工作流步骤的轨迹来深入理解。
查看搜索轨迹示例:
- 搜索词: “Black hole theories Einstein”, “Event horizon telescope radio”
- 返回结果包含大量博客文章(如 astrokidnews.com、spacefunnews.com)
- 甚至有小学生破解黑洞谜团的新闻
💡 小白注释:翻监控一看——搜索词是”黑洞理论 爱因斯坦”,太泛了!搜出来的结果里居然有”小学生破解 30 年黑洞谜团”这种娱乐新闻,正经学术论文反而被埋在后面了。这就是问题根因。
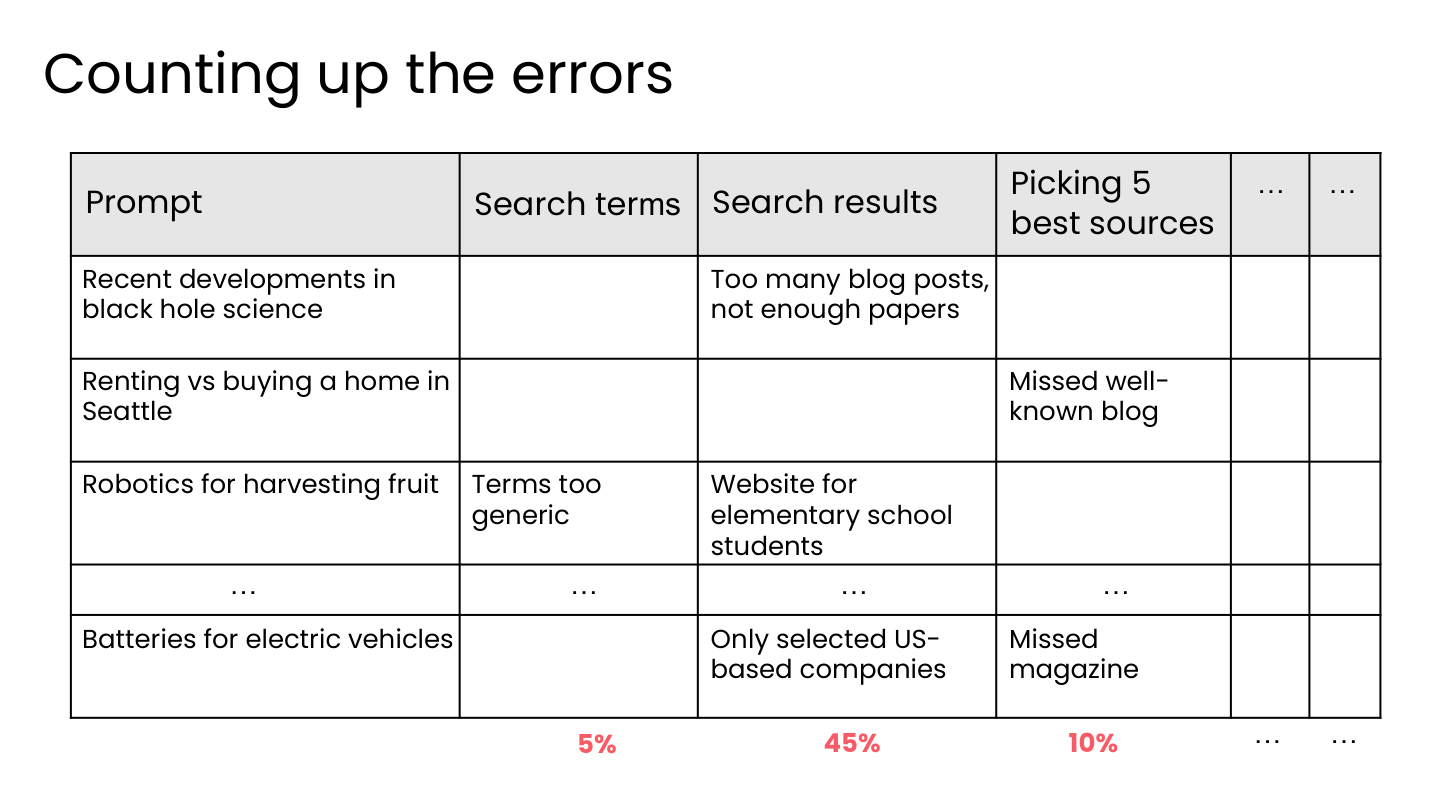
2.3 统计错误
将多个案例的错误按组件分类统计:
| 步骤 | 问题描述 | 错误占比 |
|---|---|---|
| 搜索词 | 术语过于通用 | 45% |
| 搜索结果 | 博客文章太多,学术论文不足 | 5% |
| 选择来源 | 只选了美国公司;遗漏知名博客/杂志 | 10% |
💡 小白注释:做了 100 道题,一道道翻监控统计——发现近一半错误都是因为”搜索关键词太泛”。这就是数据在说话:先改搜索,性价比最高!
2.4 错误分析技巧
- 养成查看轨迹的习惯
- 通过错误分析找出哪个组件表现不佳
- 利用错误分析结果决定重点改进方向
💡 小白注释:三原则:① 经常看监控;② 定位到具体”嫌疑人”;③ 哪里错最多就先改哪里。别凭感觉,让统计数据决定优先级。

2.5 更多错误分析案例
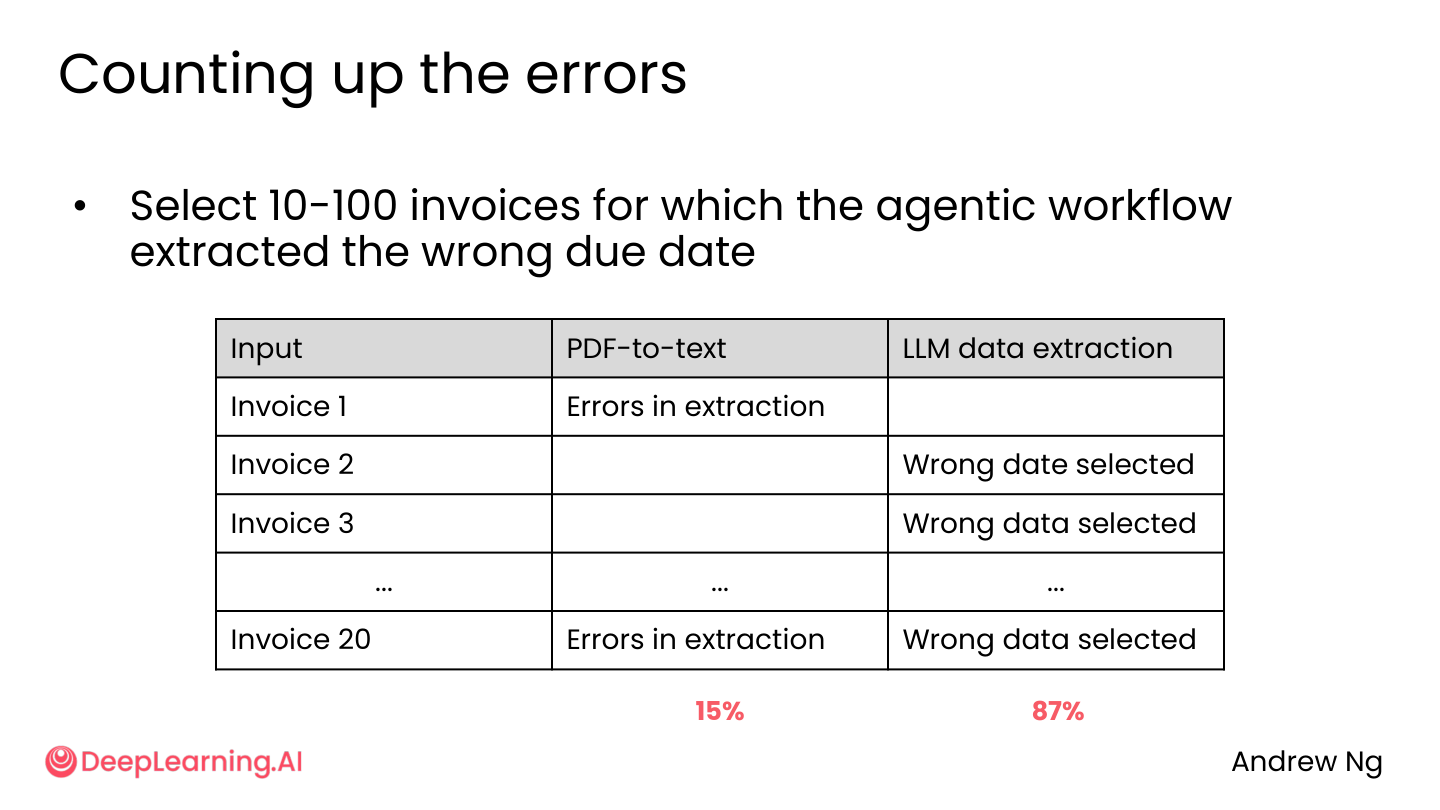
发票处理工作流
聚焦表现不佳的案例,分析各步骤错误:
- PDF-to-text 步骤: 15% 提取错误
- LLM 数据提取: 87% 选错日期
💡 小白注释:20 张发票里搞砸的那些,翻出来一分析——87% 的错误都是 LLM 提取日期时搞错的(比如把 08/20 写成 08/02),只有 15% 是 PDF 转文字时就转错了。这说明主要矛盾在”AI 读日期”这一步,而不是”PDF 识别”那一步。
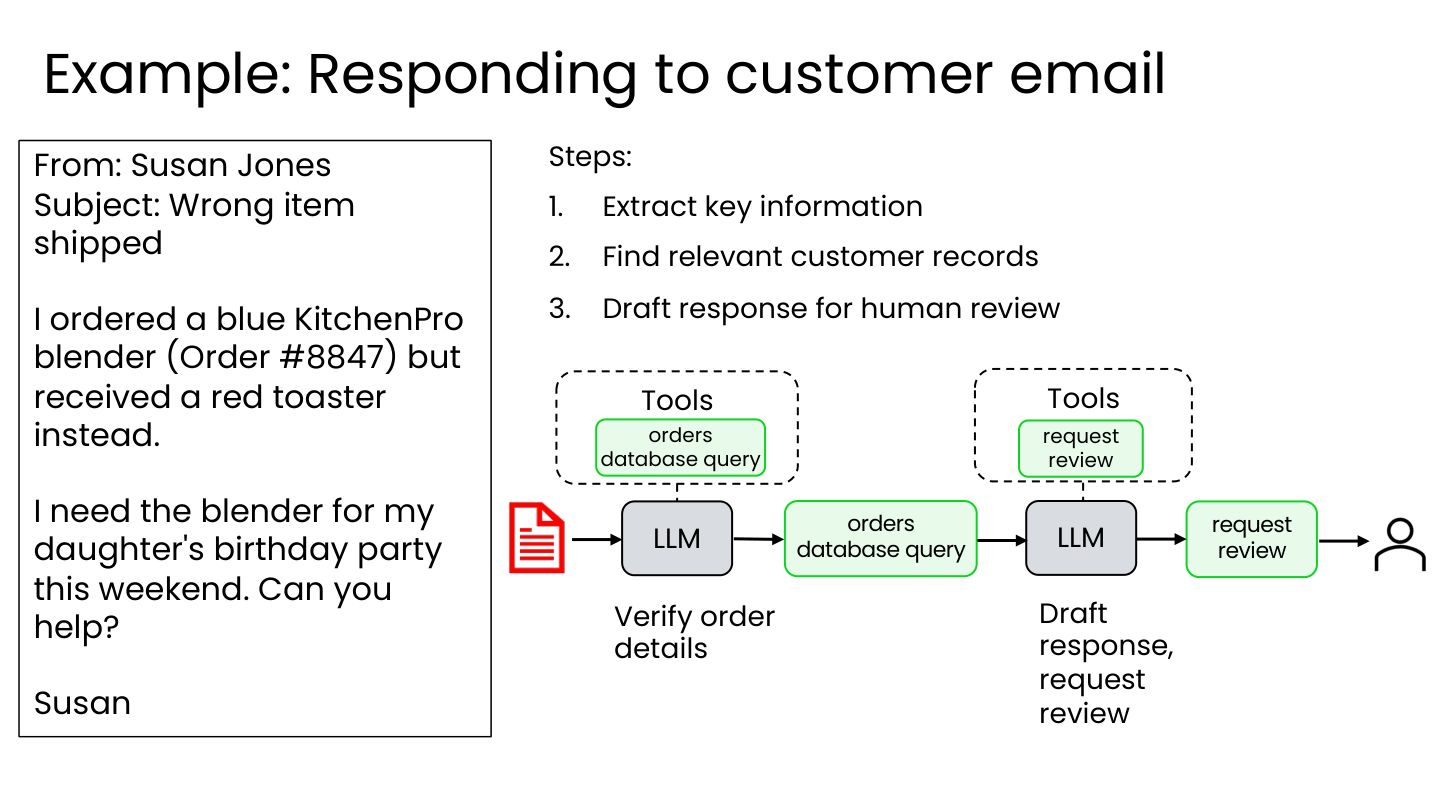
客户邮件回复
工作流步骤:
- 提取关键信息
- 查找相关客户记录
- 起草回复供人工审核
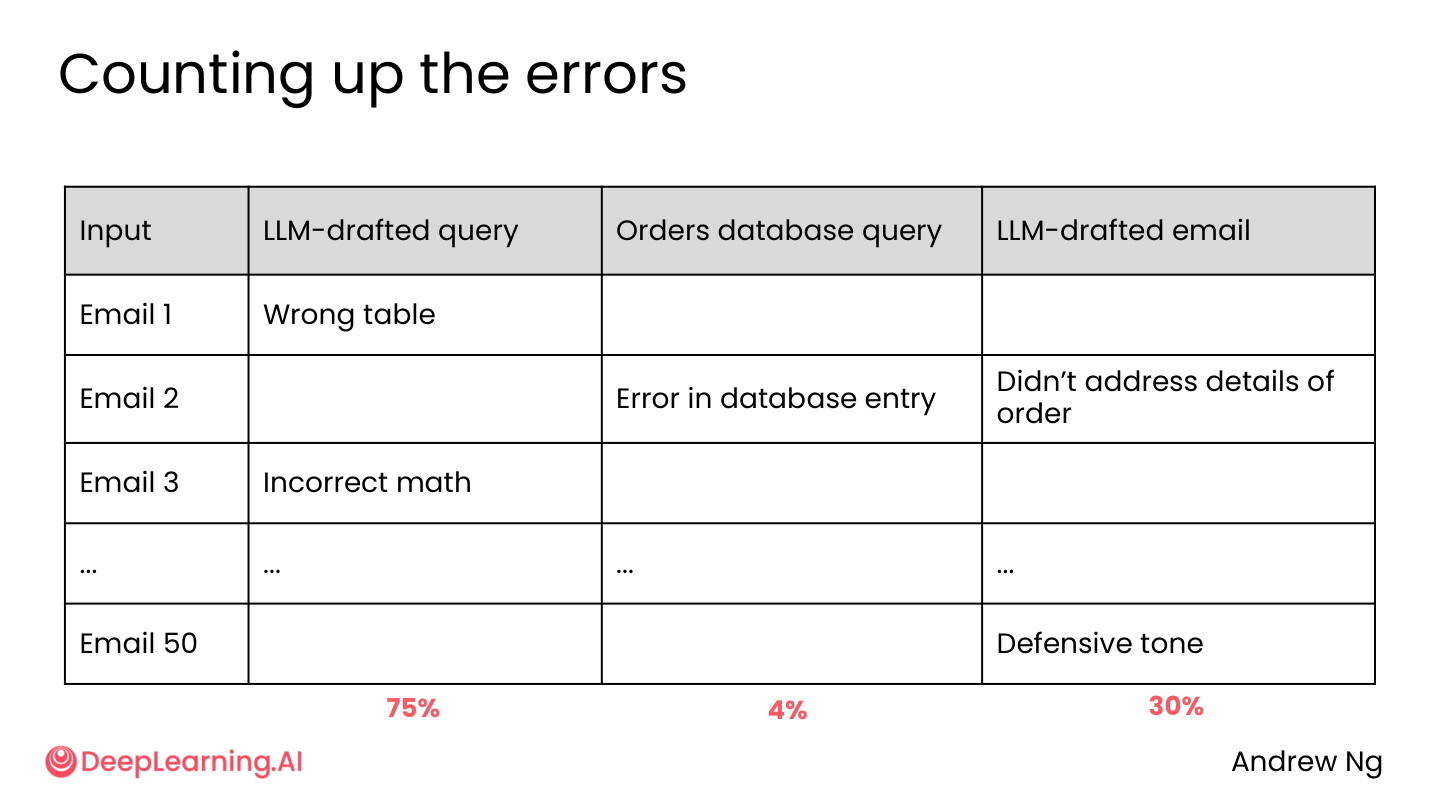
错误统计:
- LLM 起草的查询: 75% 选错表
- 订单数据库查询: 4% 数据库录入错误
- LLM 起草的邮件: 30% 未处理订单细节/计算错误/防御性语气
💡 小白注释:翻 50 封邮件的监控后发现——75% 的问题都是 AI 去数据库查订单时”找错了表格”!这才是大坑。别急着训练 AI 写邮件的语气,先把”查表”这个问题修好,收益最大。
三、组件级评估 Component-level Evaluations
3.1 为什么需要组件级评估
端到端评估成本高昂。组件级评估可以:
- 为特定错误提供更清晰的信号
- 避免端到端系统中的噪音
- 更高效的聚焦优化
- 在更小、更具体的问题上更快迭代
💡 小白注释:测一次完整流程(搜索→读文章→写文章→阅卷)要几分钟、花不少钱。如果只想知道”搜索好不好”,却每次都要跑完整个流程,就像检查轮胎气压却要把整辆车开一圈——太浪费了。直接单独测搜索,几秒钟搞定,便宜又精准。

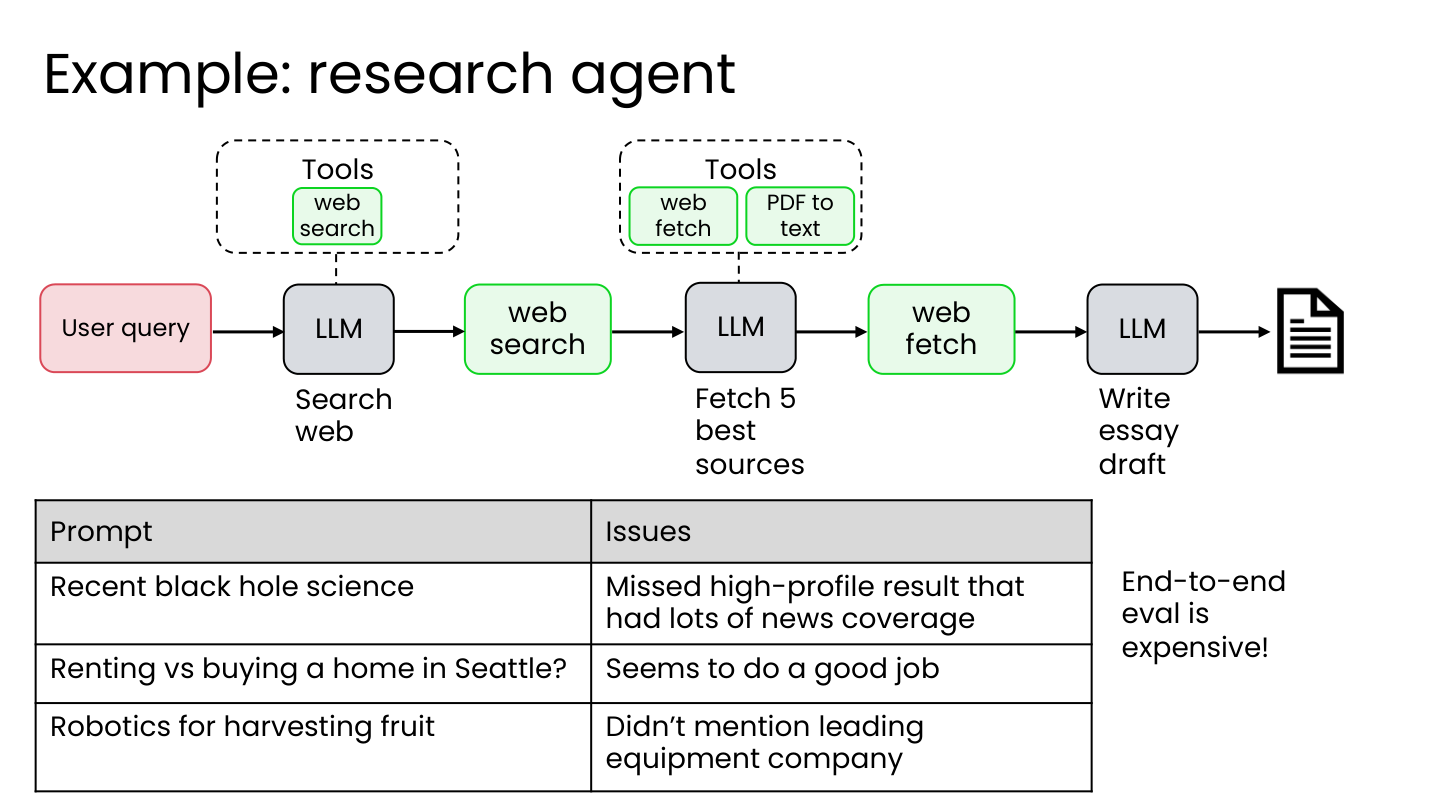
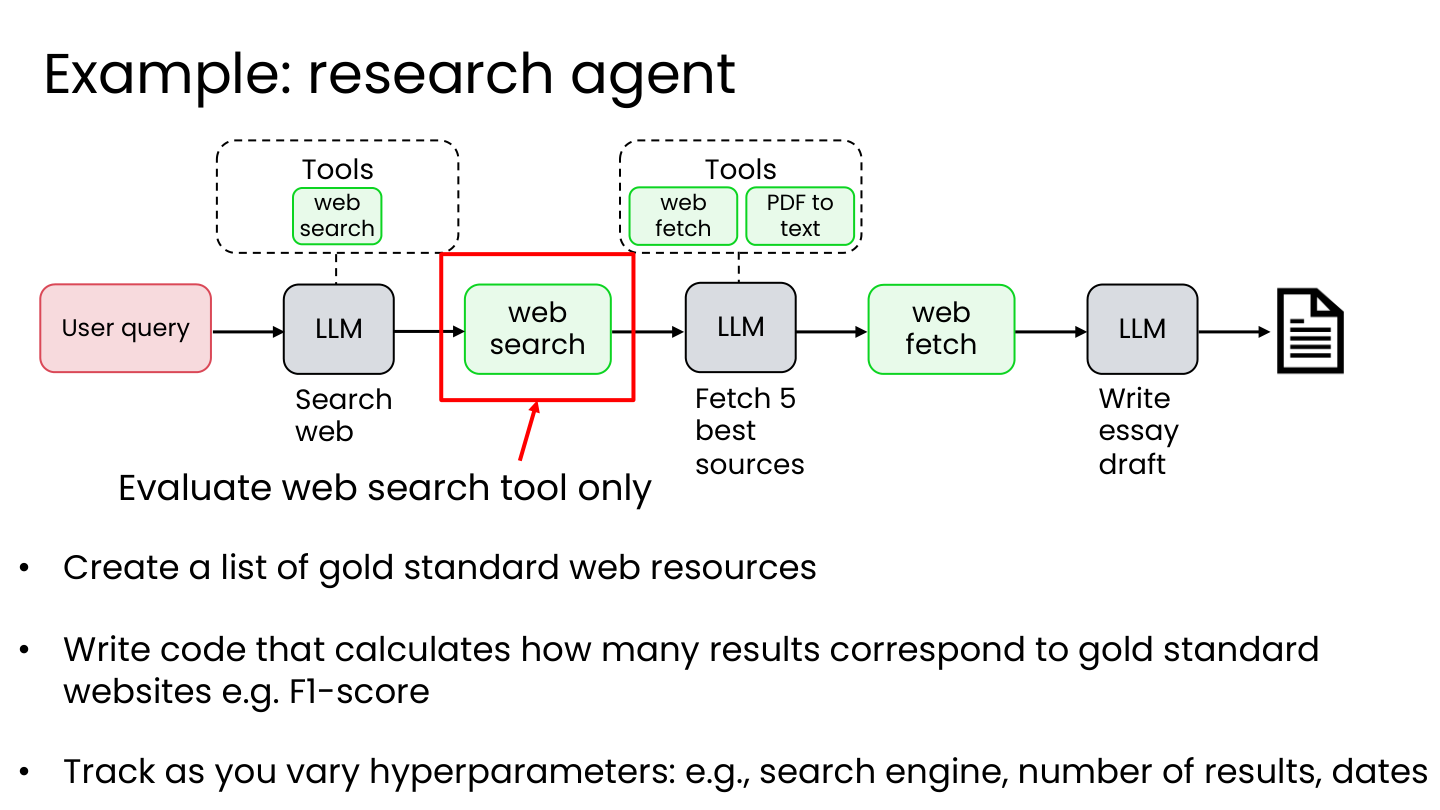
3.2 研究代理的组件评估示例
评估 web 搜索工具:
- 创建黄金标准网络资源列表
- 编写代码计算多少结果对应黄金标准网站(如 F1-score)
- 追踪不同超参数下的表现:搜索引擎、结果数量、日期范围
💡 小白注释:”单科考试”的做法:你先列一张”好网站清单”(Nature、Science、NASA 等),让 AI 搜一个话题,然后程序自动算:搜出来的 10 条结果里有几条来自”好网站清单”?换不同搜索引擎、多要几个结果、限定日期,看哪种配置得分最高。
3.3 组件级评估的好处

四、如何解决问题
4.1 改进非 LLM 组件
| 方法 | 示例 |
|---|---|
| 调整组件超参数 | Web 搜索: 结果数量、日期范围;RAG: 相似度阈值、块大小;ML 模型: 检测阈值 |
| 替换组件 | 换用不同的搜索引擎、RAG 提供商等 |
💡 小白注释:不是 AI 的锅,是工具的锅。就像奶茶机温度不对——你可以调温度(调参数),也可以直接换一台机器(换组件)。搜索引擎不好用?换谷歌。搜索结果太旧?把时间范围从”全部”改成”最近一年”。


4.2 改进 LLM 组件
| 方法 | 说明 |
|---|---|
| 改进提示 | 添加更明确的指令;添加具体示例(Few-shot) |
| 尝试新模型 | 用多个 LLM 测试,用评估选择最佳 |
| 拆分步骤 | 将任务分解为更小的步骤 |
| 微调模型 | 在内部数据上微调以提升性能 |
💡 小白注释:AI 脑子不好使时的四招:① 改说法(提示词写得更明白);② 换人(换更聪明的模型);③ 拆活(别让它一口气干完,先列大纲再找资料再写正文);④ 培训(用你的专属数据再教教它)。

4.3 案例:指令遵循能力
任务: 识别文本中的所有 PII,按类型分类列表,用 “*****” 遮盖,并用 “REDACTED: “ 分隔。
Llama 3.1 8B 的表现:
- 未正确遵循格式指令
- 遗漏部分 PII
💡 小白注释:便宜的 AI(Llama 3.1 8B)就像高中生——你让他按格式处理隐私信息,他格式写错了,还漏了几个。不是不会,是”没仔细看题目”。


GPT-5 的表现:
- 遵循了格式指令
- 识别了所有 PII
💡 小白注释:贵的 AI(GPT-5)就像博士生——格式完全正确,所有隐私信息一个不漏。这说明:不是所有 AI 都适合所有任务,简单的活便宜的能搞定,复杂的活得请贵的。

4.4 培养模型智能直觉
- 经常与模型互动
- 建立个人评估集可能很有帮助
- 阅读他人的提示以获得最佳使用灵感
- 在 Agentic 工作流中使用不同模型
- 了解哪些模型适合哪些任务类型
- 使用 aisuite 轻松切换模型
💡 小白注释:怎么知道哪个 AI 适合干啥?多试!就像你用手机 App——用多了自然知道哪个叫车快、哪个点外卖便宜。固定测几个你关心的任务,看哪个得分高。工具 aisuite 可以帮你一键切换不同 AI 做对比。

五、延迟与成本优化
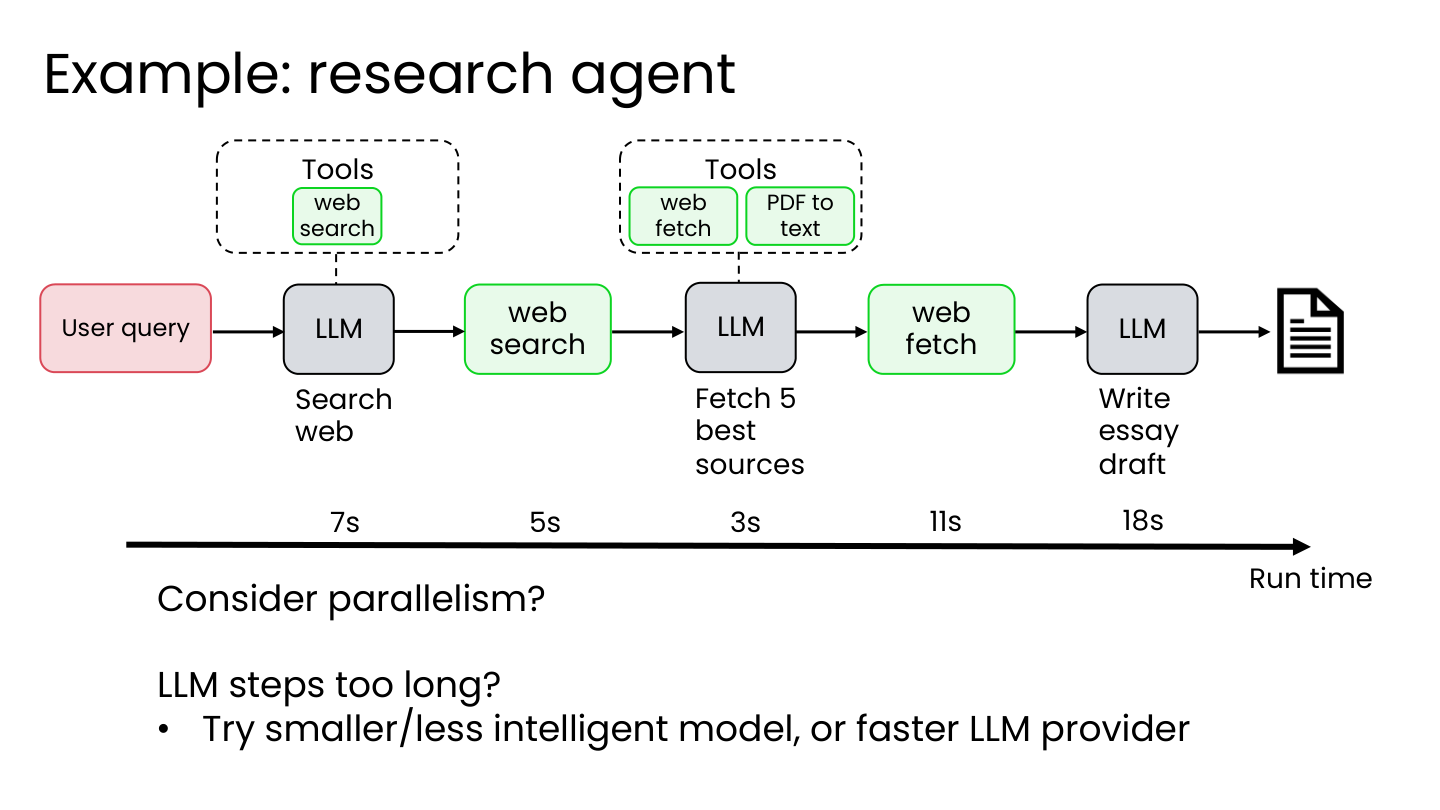
5.1 延迟优化
分析运行时间:
- Web 搜索: 3s
- Fetch 来源: 5s
- LLM 撰写: 11s
- PDF-to-text: 7s
- 其他 LLM 步骤: 18s
优化方向:
- 考虑并行化
- LLM 步骤是否过长?
- 尝试更小/更快的模型或更快的 LLM 提供商
💡 小白注释:客人等奶茶等烦了。分析每步花多久——搜索 3 秒、读网页 5 秒、AI 写文章 11 秒……哪些能同时做?比如搜索和读 PDF 可以并行。AI 写东西太慢?换个”小脑瓜”但手快的模型,可能只要 3 秒。

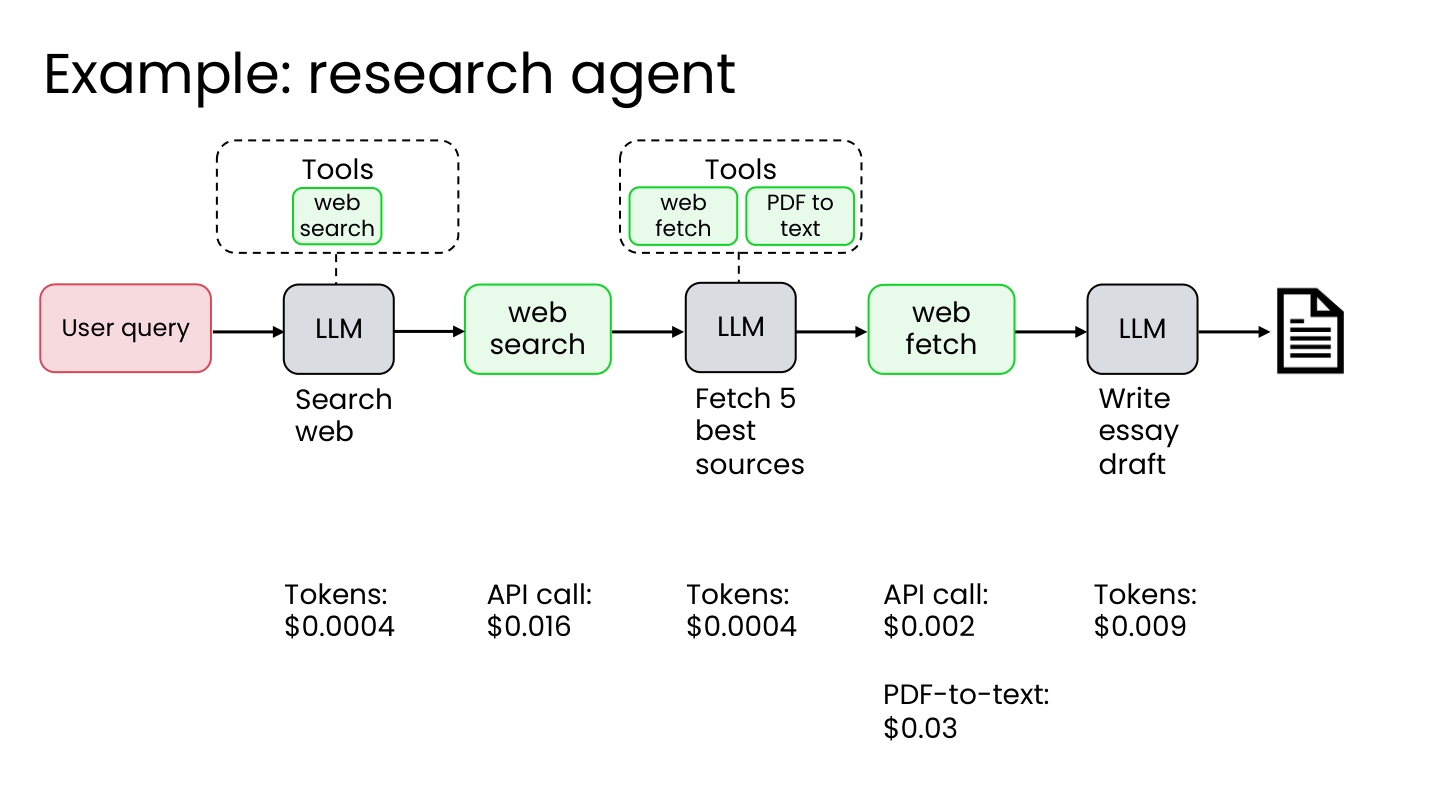
5.2 成本核算
成本构成:
- LLM 步骤: 按 token 付费
- API 调用工具: 按 API 调用付费
- 计算步骤: 基于服务器容量/成本
研究代理成本示例:
- Web 搜索 API: $0.016
- Fetch 来源 API: $0.002
- LLM token 1: $0.0004
- LLM token 2: $0.0004
- LLM token 3: $0.009
- PDF-to-text: $0.03
💡 小白注释:一次研究报告大概花 0.06 美元(约 4 毛人民币)。听着不多?但一天跑 10 万次就是 4 万块。每一笔小钱乘以次数就是大数字。搞清楚钱花在哪——是 AI 说话太贵?还是搜网页 API 贵?针对性优化。

六、开发流程总结
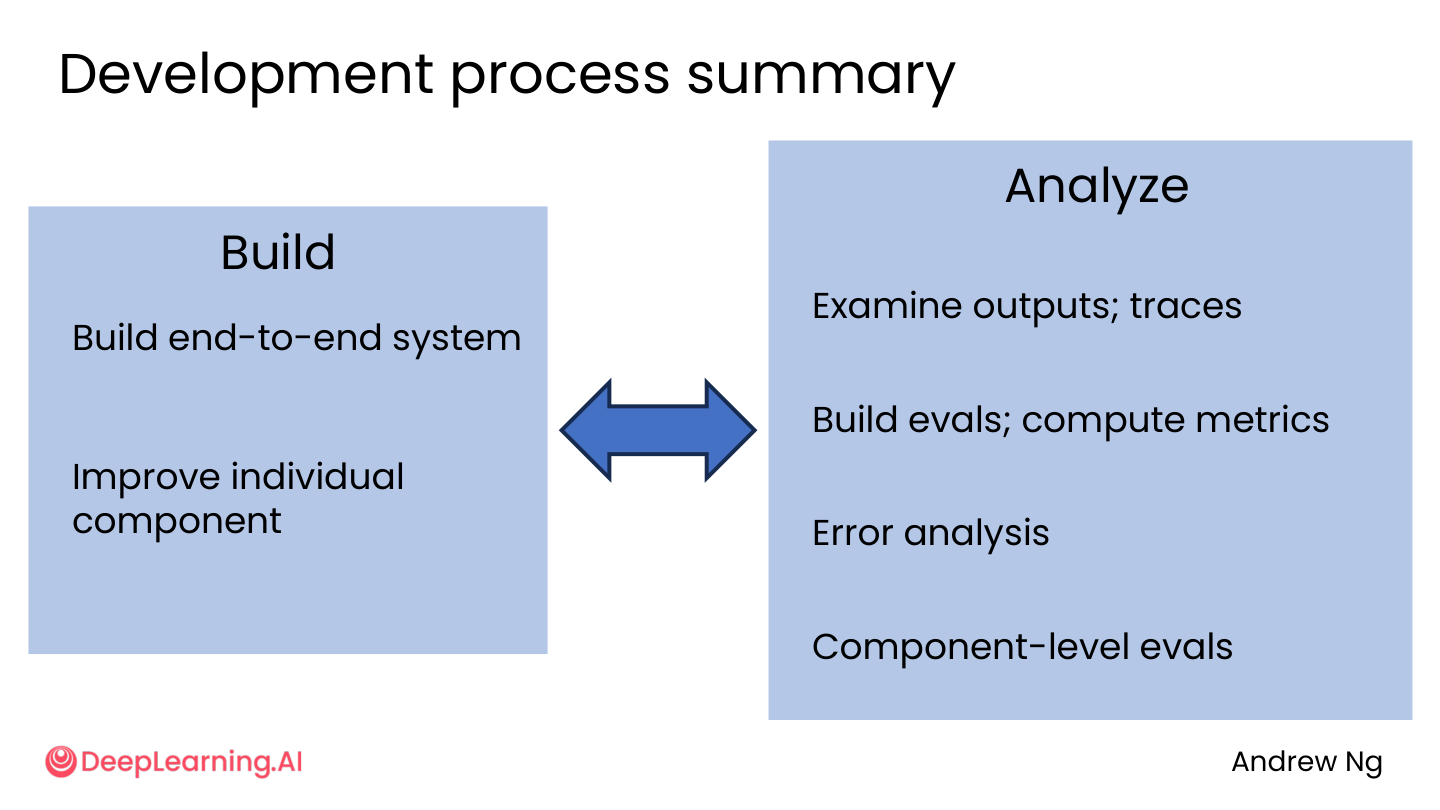
迭代开发循环
1
2
3
4
5
6
7
8
9
10
11
12
13
构建端到端系统
|
v
检查输出 + 查看轨迹
|
v
错误分析 --------> 组件级评估
| |
v v
改进单个组件 <---- 建立评估 + 计算指标
|
v
(重复)
💡 小白注释:一张图说清全部——先搭起来能跑,然后看监控、统计哪里错最多,针对性出考卷、做改进,改完再测。循环往复,越做越好。核心就三句话:先跑起来、用数据说话、循环迭代。

附录:全部幻灯片
| 页码 | 内容 |
|---|---|
| 1 | 封面: M4 Practical tips for building agentic AI |
| 2 | 目录: Evaluations |
| 3 | 案例: 发票处理工作流 |
| 4 | 创建评估:日期提取 |
| 5 | 用评估驱动开发流程 |
| 6 | 案例: 营销文案助手 |
| 7 | 创建评估:文本长度 |
| 8 | 案例: 研究代理 |
| 9 | 创建评估:LLM-as-a-Judge |
| 10 | 评估的两个维度 |
| 11 | 设计端到端评估的技巧 |
| 12 | 目录: Error Analysis |
| 13 | 研究代理错误分析 |
| 14 | 可能的原因分析 |
| 15 | 查看轨迹示例 |
| 16 | 统计错误 |
| 17 | 错误分析技巧 |
| 18 | 更多错误分析案例 |
| 19 | 发票处理错误分析 |
| 20 | 统计错误占比 |
| 21 | 客户邮件回复案例 |
| 22 | 邮件回复错误统计 |
| 23 | 目录: Component-level evaluations |
| 24 | 端到端评估成本高昂 |
| 25 | 评估 web 搜索工具 |
| 26 | 组件级评估的好处 |
| 27 | 目录: How to address problems |
| 28 | 改进非 LLM 组件 |
| 29 | 改进 LLM 组件 |
| 30 | 案例: 指令遵循 |
| 31 | Llama 3.1 8B 结果 |
| 32 | GPT-5 结果 |
| 33 | 培养模型智能直觉 |
| 34 | 目录: Latency, cost optimization |
| 35 | 延迟分析 |
| 36 | 成本核算 |
| 37 | 研究代理成本示例 |
| 38 | 目录: Development process summary |
| 39 | 开发流程总结图 |
| 40 | End of M4 |